
Mark Joseph, Algirdas Avižienis
Proceedings of 1988 IEEE Symposium on Security and Privacy, pp. 52-58
ISBN 0-8186-0850-1
April 1988
 Download PDF (679.8Kb) (You need to be registered on forum)
Download PDF (679.8Kb) (You need to be registered on forum)The applicability of fault tolerance techruques to computer security problems is currently being investigated at the UCLA Dependable Computing and Fault-Tolerant Systems Laboratory. A recent result of this research is that extensions of Program Flow Monitors and N-Version Programming can be combined to provide a solution to the detection and containment of computer viruses. The consequence is that a computer can tolerate both deliberate faults and random physical faults by means of one common mechanism. Specifically, the technique described here detects control flow errors due to physical faults as well as the presence of viruses.
This paper addresses the computer virus problem as fist introduced in [Cohe 84]: “A computer virus is a program that can infect other programs by modifying them” (i.e., their executable file) “to include a possibly evolved copy of itself. With the infection properqy, a virus can spread throughout a computer system or network using the authorizations of every user, using it to infect their programs. Every program that gets infected may also act as a virus and thus the infection grows.” Additionally, we address the case where a Trojan horse in a program handling tool (e.g., a compiler) infects an unprotected program it is manipulating.
Some apparent properties of viral infections are: (1) most viruses add themselves to the beginning of an executable file, (2) the date of the most recent write to an executable tile is likely to get changed, (3) the size of an infected executable file is very likely to be larger than the original, and (4) the behavior of an infected executable will change. The approaches taken here use item (4) as a basis for detection and containment mechanisms. The scheme presented in [Denn 86] also monitors system behavior to detect viruses and other threats; however, it does that at a coarse-grain level of monitoring. The virus detection approach described here utilizes a fine-grained monitoring of program control flow for detection.
The general taken in this paper is somewhat different from those taken by current computer security researchers. We treat computer viruses as a fault tolerance problem, and thus we apply a fault tolerance perspective in our attempt to prevent viruses from affecting proper system service.
In a fault tolerance approach it is assumed that faults will occur in the system and that run-time mechanisms must be included in the design in order to tolerate them. These mechanisms are complementary to fault avoidance (e.g., formal verification) techniques which aim to remove all faults (or flaws, hardware and software) throughout a computer system’s life-cycle. All the faults to be handled are defined and characterized by standard fault classes [Aviz 87]. Once this is done, error detection, masking, error recovery, and error containment boundaries are selected. This has been the general approach that has led to the proposed solution to computer viruses presented here. This approach has also been applied to other security threats (e.g., trap doors, denial-of-service, covert channels) [Jose 88].
The rest of the paper is organized as follows: section 2 presents a fault tolerance oriented characterization of computer viruses, sections 3 and 5 provide introductions to Program Flow Monitors (PFM) and N-Version Programming (NVP) respectively, section 4 extends the basic program flow monitor approach in order to detect computer viruses, and section 6 discusses how NVP can eliminate the effects of a Trojan horse in program handling tools.
A fault is the identified or hypothesized cause of an error or of a failure. An error is an undesired state of a resource (computing system) that exists either at the boundary or at an internat point in the resource and may be experienced as a failure when it is propagated to and manifested at the boundary. A failure is a loss of proper service (i.e., specified behavior) that is experienced by the user (i.e., a human or anothers system) at the boundary of a resource [Aviz 86].
A design fault is a human-made fault (or flaw), resulting in a deviation of the design from its specification. It includes both implementation faiths (e.g., coding errors) and interpretation faults (i.e., misinterpretation or misunderstanding of the specification, rather than a mistake in the specification), and can occur in both hardware and software. For example, failing to check input values is an interpretation fault, while being unable to retrieve records from a database is an implementation fault [Aviz 84]. Design faults can partially be characterized by the fault class “by intent,” which includes both random (i.e., “accidental”) and deliberate faults [Aviz 86]. The idea of applying fault tolerance techniques that are used to address random faults, to the tolerance of deliberate ones is further explored in [Jose 87].
Figure 1 is a fault tolerance oriented characterization of the behavior of a computer virus. Initially a computer virus can start as a special type of Trojan horse that injects or infects an executable file with a virus. The Trojan horse is a deliberate design fault, and causes an “error” by changing the state of the executable file resource. Nex~ the infected executable spreads or propagates the error to other executable. Thus, the error becomes the fault causing other errors, and a typical error propagation occurs just as it does in the case of a random fault. The characterization of a virus as both a fault and an error indicates that viruses should be countered with two mechanisms, rather than just one.
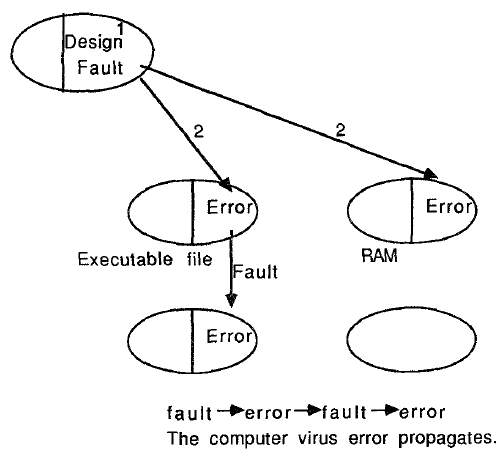
Figure 1 Computer Virus: A Fault and an Error
Figure 2 provides a somewhat different perspective by indicating the types of damage a computer virus can cause. The figure shows that a computer virus design fault can potentially cause the following errors: loss of integrity of function and data, i.e., the actions of the Trojan horse injecting the virus (see section 5), unauthorized modifications of programs, unauthorized disclosure, denial-of-service, and spooling (e.g., the virus pretends to be the program it has infected). Note, that ‘DAC’ in the figure refers to discretionary access control.
The two life stages of a virus (i.e., first a design fault via a Trojan horse, and then an error propagating or infecting executable) can be detected and recovered from differently. The deliberate design fault via a Trojan horse can be masked out with the use of N versions of that program (e.g., 3 versions of a compiler, see section 6). However, since NVP is too expensive to be applied everywhere, it must be accompanied by a mechanism that can detect the computer virus in its error stage. A scheme to detect and recover from the viral infection is presented in section 4 and is an extension of PFMs [Mahm 88].
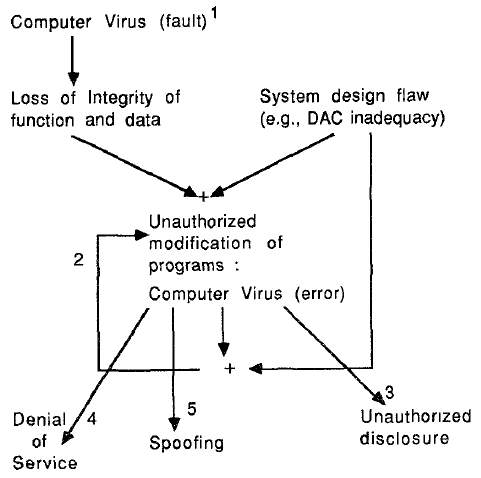
Figure 2 Fault Tree for a Computer Virus
A Program Flow Monitor (PFM) is a concurrent error detection mechanism that can be used in the design of a fault-tolerant computer. It is basically a watchdog processor, which is “a small and simple coprocessor used to perform concurrent system-level error detection by monitoring the behavior of the main processor” [Mahm 88]. It is used to detect control flow errors due to transient (e.g., single event upset) and permanent faults.
Control flow errors are “incorrect sequences of instructions, branch to wrong addresses, branching from a wrong address, etc.”. These “errors can be the result of faults in the instruction register, the program counter, the address register, decoding circuitry, memory addressing circuitry, etc.” [Mahm 88].
Detection of control flow errors is done by comparing dynamic characteristics of program behavior with the expected behavior. One approach is to associate a signature to a sequence of assembly language statements that do not contain any control flow change instructions (e.g., branches, subroutine calls). The signatures are derived from the assembly language statements. After generation, the signatures can be stored in a control flow graph (CFG), embedded graph program, or embedded in the executable code. The signatures and control flow graph are generated by a compiler and linker [Mahm 88].
As a program runs on a CPU, the fetched instructions go through a signature generator which is based on a linear feedback shift register (LFSR). Thus, a signature is computed primitive polynomial (e.g., 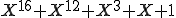 . When a control flow change instruction passes through the signature generator, the current signature value is passed to the PFM. The PFM then compares the run-time generated and link-time generated signatures, and a disagreement indicates an error condition. If a control flow graph is used, then it is traversed as these signature comparisons are made.
. When a control flow change instruction passes through the signature generator, the current signature value is passed to the PFM. The PFM then compares the run-time generated and link-time generated signatures, and a disagreement indicates an error condition. If a control flow graph is used, then it is traversed as these signature comparisons are made.
The applicability of a PFM-based scheme to the detection of computer viruses is based on the observation that actions of a virus also represent an invalid sequence of instructions. However, the basic PFM schemes must be extended to prevent a virus from hiding from it.
The present PFM schemes are designed to detect random physical and possibly some design faults, but not deliberate faults. Thus, the existing schemes are susceptible to all but a few viral attack scenarios.
The first weakness against viruses is that PFMs use only one primitive polynomial to compute all signatures. Thus, a computer virus fault compiled on the monitored machine will have valid signatures generated for it. If a CFG is used, then the virus would have to add its signatures to it.
A computer virus error propagating over a network may not have valid signatures, and thus would be detected by even the existing PFM designs. However, the backward recovery mechanisms used with a PFM (e.g., rollback) would end up mistaking the virus as a permanent fault. This inability to distinguish between viruses and random faults is the second weakness of existing PFM designs. Any PFM-based scheme must have a recovery approach that can identify a viral attack, since the recovery action is different for transients, permanents, and viruses.
The following five extensions are made to a PFM scheme that utilizes a control flow graph (CFG):
The rollback procedure allows the identification of the type of fault as follows. First, if the initial error was caused by a transient fault, the recomputation will succeed, and the program will continue on after a successful signature check. Second, if the initial error was due to a permanent fault, the fault will still cause an improper dynamically generated signattue after the rollback. For some faults, the second signature will not be identical to the first invalid signature, and a permanent physical fault is indicated. Third, the initial error may have been caused by a permanent fault which causes the identical error to appear again. Generation of the identical, but incorrect, signature after the first rollback will require diagnostics to be run to locate the permanent fault. Lastly, if diagnostics do not detect a fault, then a high probability exists that a virus error has been detected.
For computer architectures without effective process isolation (e.g., the Intel 8086, the non-protect mode of the Intel 80286), the memory address for writing to memory can be monitored by the PFM. This will detect a viral infection of an executable during run-time (e.g., a block move of virus code into a process’s unused stack space). This approach is a design option of a PFM, not a real extension of the technique. In fact, all externally visible actions of a CPU can be monitored by the PFM.
A PFM-based virus detection approach offers some significant advantages. First, it protects an executable even during run-time, while the schemes presented in [Pozz 86] and [Cohe 87] do not provide this protection. Second, it also provides detection of errors caused by physical, and possibly certain design faults. Third, standard PFM schemes can be extended for virus detection at a modest additional cost. Fourth, no run-time performance degradation occurs, after CFG decryption. Finally, the PFM is virus proof, since all of its components are either hardwired or ROM based, and the PFM local memory, as well as the LFSR can only be accessed by the PFM.
The additional costs of the PFM-based approach are as follows: (a) the compiler and linker pair must assign polynomials (b) the CFG should be encrypted, and the keys for each CFG must be managed and protected (c) modifications to existing compilers and linkers are needed, (d) extra mechanisms for atomic I/O are required, and (e) due to the overhead associated with the setup of a CFG in a PFM memory, this scheme is applicable to environments in which process context switches are not frequent (e.g., multiprocessor applications, embedded applications, personal computers).
Several definitions for integrity in a security context are presented in [Port 85]. The relevant definitions are:
Each item above is referred to by : “integrity-#” Integrity-2 and integrity-5 are classical concerns, since these are what the current state-of-the-art can ensure [Biba 77] [Voyd 83].
[Port 85] later continues with the interesting statement that “..., we first eliminate integrity-3 and 4, until we have a way to deal with design issues.” Integrity-1 is also bypassed for approximately the same reason. However, through the use of fault tolerance techniques integrity-1, 3, and 4 can be supported. Integrity-3 and 4 from a fault tolerance perspective involves ensuring proper service of a function (software or hardware) with respect to a defined fault class. Integrity-1 can be partially provided by preventing a failing function from generating incorrect data (e.g., for missile targeting).
We designate the items integrity-1, 3 and 4 as ensuring “integrity of function and data.” Two examples of violations to be avoided are: inaccurate (old) data deliberately placed into a database, and incorrect actions (e.g., fire a missile at an ally). It was observed from the very beginning of this research that these integrity concerns were very close to those addressed in both hardware and software fault tolerance.
NVP is an approach that aims to provide reliable softwme by means of design fault tolerance [Aviz 85]. N > 2 versions of one program are independently designed and implemented from a common specification (or even from two or more specifications). All N versions are executed concurrently, typically on an N-processor computer system. During execution, the versions periodically fotm a consensus on intermediate results and on the futal result. As long as a majority of versions produce correct results, design faults in one or more version will be detected and masked out. The strength of this approach is that reliable computing does not depend on the total absence of design faults.
A natural extension of this approach is to employ NVP to maintain the integrity of function and data by masking out the incorrect outputs of deliberate design faults. The probability of identically behaving versions of malicious logic appearing in a majority of the N versions of programs is diminished due to the independent design, implementation, and maintenance of multiple versions.
The design fault stage of a computer virus can exist in a program handling tool (e.g., a compiler), as well as in an ordinary application program [Cohe 84] [Pozz 86]. Thompson [Thom 84] gives an example of how a Trojan horse in a C-language compiler can implant a trap door into a UNIX* (* A trademark of AT&T Bell Laboratories.) login program. In this example, the Trojan horse is particularly insidious in that it is designed to detect its own compilation (i.e., the C compiler’s source code) and then to implant a copy of itself into the generated executable. Furthermore, the actual code for the Trojan horse can be removed from the compiler’s source after its first compilation because of the preceding property. This makes the detection of this Trojan horse attack by source code inspection and verification impossible. Currently, addressing the correctness of program handling tools is beyond the requirements for class A1 secure systems [DoD 85], and thus it is a deficiency in any current defense. In summary, a virus can infect a program during an editing session, compilation, assembly, linking, or loading.
In addition, assurance of the correctness of hardware and firmware (i.e., the absence of random and deliberate hardware design faults) for the TCB of a system is also beyond A1 for the hardware of both development environments and operational systems. Current research in secure execution environments is directed towards the use of advanced formal verification techniques for both hardware and software [Bevi 87]. While this research looks promising, a solution of the problem for large, complex systems is not certain for the near future. Specifically, the approach used for hardware verification does not include timing, nor system behavior in the presence of faults (i.e., the system may be broken into due to deliberately induced faults).
In this section we propose a potential alternative to formal verification. It is the design of secure development tools based on N-Version programming, and secure development hardware based on hardwme design diversity. A secure 3-version (two version systems are susceptible to denial-of-service attacks [Jose 87]) C-language compiler, for example, would operate as follows. Consensus voting between versions would periodically occur on several items: (a) parts of the local state, (b) temporary output at each phase of compilation, (c) actions which manipulate files, and (d) the final generated code. The voting locations (“cc-points”) and the values to be voted on (“cc-vectors”) need to be clearly defined in the compiler’s design specification before it is built. (We note that for this to work strict guidelines on code generation and optimization must be provided.) Item ‘c’ above includes an “action voting” requirement for NVP (i.e., the external actions taken by a process, for example, the system calls, are voted on, as well as, the data generated [Jose 88]).
Experiments at UCLA have already demonstrated the feasibility of constructing an teliable NVP text processor [Chen 78]. However, an NW-based tool is just as vulnerable to a computer virus error as any other executable file. Thus, if a virus infects a majority of the versions the NVP scheme would be defeated. To prevent this from occurring, each version must be monitored by a PFM, or protected by a scheme such as presented in [Pozz 86], [Cohe 87].
In summary, the reason why NVP-based program handling tools can counter the design fault stage of a virus, and also many actions of general Trojan horses, is that all maliciously generated actions are masked out by the N version consensus operation.
The need for fault-tolerant and secure computing systems is becoming quite evident (e.g., the SDI application). This has sparked the exploration of the issues concerning the design of computing systems that possess both attributes. Fault tolerance and security concerns are not disjoint. For example, security considerations may prevent the use of rollback to recover from an error [Turn 86].
Attacks on a computer system can take one of three forms: from completely outside the computing system, from a legitimate, authorized user trying to extend his or her allowed access rights, and from within the computer system itself due to design flaws purposely planted by its designers [Jose 87]. It should no longer be acceptable to consider only the classical security concerns of preventing the unauthorized disclosure of sensitive information, and the unauthorized modification of information and programs. The elimination of the effects of malicious logic must be addressed, and this problem reveals many similarities to problems in fault tolerance.
It is envisioned that in the near future most military computer systems will require both security and fault tolerance properties. Other critical systems may follow soon (e.g., financial, point-of-sale, and plane reservations) where failures, deliberate or otherwise, will be unacceptable due to loss of life, finances, andlor privacy. For example, as of 1987, an average of a trillion dollars in payments, on a typical day, are exchanged by banks over electronic telecommunications networks [FRBS 87]. This represents a potential financial disaster if fault-tolerant, secure, and high integrity communications and processing are not guaranteed.
The approach presented in this paper is just one step towards a cost-effective design of a fault-tolerant, secure computing system, The extension of PFMs is an excellent example of a fault tolerance technique that solves both accidental and deliberate faults: the detection of computer virus errors, and control flow errors due to transient and intermittent faults. We note that extended PFM, by itself, does not protect against denial-of-service [Glig 83] due to repeated infection of the same executable.