
Eric Filiol
International Journal of Computer Science, vol. 2, number 1, 2007, pp. 70-75
ISSN 1306-4428
April 2007
 Download PDF (369.41Kb) (You need to be registered on forum)
Download PDF (369.41Kb) (You need to be registered on forum)This paper presents a formalisation of the different existing code mutation techniques (polymorphism and metamorphism) by means of formal grammars. While very few theoretical results are known about the detection complexity of viral mutation techniques, we exhaustively address this critical issue by considering the Chomsky classification of formal grammars. This enables us to determine which family of code mutation techniques are likely to be detected or on the contrary are bound to remain undetected. As an illustration we then present, on a formal basis, a proof-of-concept metamorphic mutation engine denoted PB MOT, whose detection has been proven to be undecidable.
Keywords Polymorphism, Metamorphism, Formal Grammars, Formal Languages, Language Decision, Code Mutation, Word Problem.
Polymorphism and metamorphism are the two techniques dedicated to hinder sequence-based antiviral detection. The principle is to cancel as much as possible any potential fixed element in a malware code that would represent a potential detection pattern. Polymorphism has formerly been introduced by Fred Cohen [5] with the concept of Largest Viral Set while metamorphism has appeared in the early 2000s as a response to the polymorphism's inherent limitations.
From a theoretical point of view [20], [21], the core of a polymorphic malware is its kernel which is made up of an infection trigger condition1 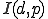 , a payload routine
, a payload routine 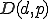 , the corresponding payload trigger condition
, the corresponding payload trigger condition 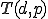 and a selection function
and a selection function 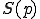 (of target programs to infect). It is precisely the latter function which is in charge of the code mutation.
(of target programs to infect). It is precisely the latter function which is in charge of the code mutation.
Metamorphic viruses differ from polymorphic viruses since their respective selection function are different. While all polymorphic forms of a virus share the same kernel, the metamorphic forms of a virus have a completely different kernel. Consequently, if detection remains tractable for some classes of polymorphism - the kernel does not change during the mutation process and thus can be used as a detection pattern -, it becomes far different as far as metamorphism is concerned.
There are very few theoretical results concerning the detection complexity of code mutation techniques. This problem has been addressed very recently only. D. Spinellis has proved [17] that detection of bounded-length polymorphic viruses is an NP-complete problem. Zuo and Zhou [20] have then proved that the set 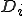 of polymorphic viruses with an infinite number of forms is a
of polymorphic viruses with an infinite number of forms is a 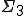 -complete set. Unfortunately, no results is known for other classes of polymorphic viruses and for the general case of metamorphism. Many open problems still remain.
-complete set. Unfortunately, no results is known for other classes of polymorphic viruses and for the general case of metamorphism. Many open problems still remain.
Up to now, only very few examples of metamorphic codes are known to exist. The most sophisticated one is the MetaPHOR engine whose essential feature is a certain amount of non-determinism. Experiments in our laboratory showed that existing antivirus software can be very easily defeated by MetaPHOR-like technology. However, the analysis of this engine [9, Chap. 4] has proved that its metamorphic techniques still belong to trivial classes.
Our research thus focused on the formalisation of metamorphism by means of formal grammar and languages. We aimed at identifying the different possible classes of possible code mutation techniques. The first results, which are presented in this paper, enable to assert that detection complexity of code mutation techniques can be far higher that NP-complete and that for some well-chosen classes, detection is an undecidable problem.
The links between polymorphism and formal grammars has been introduced in [16] for the first time. Unfortunately, the author did touch on this issue only. Metamorphism is not addressed at all. Some aspects are dealt with in a very naive way and we will prove in this paper that some of its conclusions are totally wrong.
This paper is organised as follows. Section II presents the main theoretical tools of computability theory we use throughout this paper. Section III then explains how code mutation techniques can be modelled by formal grammars and how their detection can be reduced to the problem of deciding a language. Section IV will then presents our proof-of-concept metamorphic engine, denoted POC PBMOT we have designed in order to validate our theoretical model. In particular, we will show that detecting this engine is an undecidable problem. Section V finally concludes and present some future work.
Let us first recall basic notation and concepts we will use throughout this paper. We consider a finite set 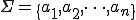 as an alphabet whose elements are called symbols. A sequence of symbols of
as an alphabet whose elements are called symbols. A sequence of symbols of 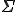 is called a chain
is called a chain 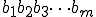 with
with 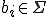 and
and 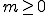 . The concatenation of two chains
. The concatenation of two chains  and
and 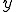 is the chain
is the chain 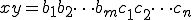 . Let
. Let 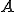 and
and 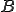 two sets of chains defined over . Then we can
define the following sets:
two sets of chains defined over . Then we can
define the following sets:
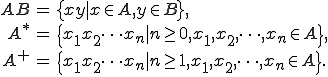
This notation enables us to introduce the concept of formal grammar.
Definition 1: [14] A formal grammar 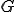 is the 4-tuple
is the 4-tuple 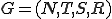 where:
where:
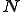 is a set of non-terminal symbols;
is a set of non-terminal symbols;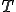 is an alphabet of terminal symbols with
is an alphabet of terminal symbols with 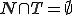 ;
;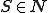 is the start symbol;
is the start symbol;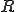 is a rewriting system, that is to say a finite set of rules
is a rewriting system, that is to say a finite set of rules 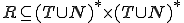 , such that
, such that 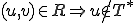 (we cannot rewrite chains which contain only terminal symbols).
(we cannot rewrite chains which contain only terminal symbols).The rewriting system (still known as semi-Thue system) over is in fact a finite subset of 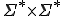 . In other words, it is the set
. In other words, it is the set 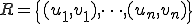 . A pair
. A pair 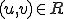 is a rewriting rule or production. It is denoted
is a rewriting rule or production. It is denoted 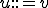 for short (instead of
for short (instead of 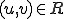 ).
).
A rewriting system R enables to define a rewriting relation, denoted 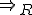 which is defined as:
which is defined as:
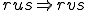 if and only if and
if and only if and 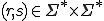 .
.
This means that we can build the chain 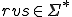 directly (e.g. in one step) from the chain
directly (e.g. in one step) from the chain 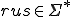 .
.
Example 1: [12] Let us consider 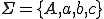 and
and 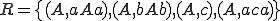 .
.
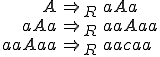
This relation allows to define a reflexive and transitive closure for the relation 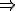 . We will denote it
. We will denote it 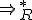 . This relation is defined, for every
. This relation is defined, for every 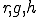 in
in 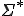 by:
by:
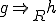 then
then 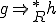
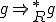
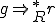 and
and 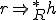 then .
then .Equivalently, two words are related with respect to this relation, if and only if one can be produced from the another. As an example, in the previous example, we can replace the symbol by .
A Thue system is a semi-Thue system in which the relation is symmetric. It is consequently denoted 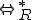 . Let us consider the following example.
. Let us consider the following example.
Example 2: Let us consider the grammar 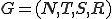 with
with 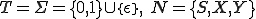 and defined by:
and defined by:
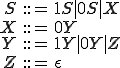
This grammar builds every chain containing at least one zero.
A formal language is finally defined by the set 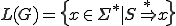 with respect to the grammar . It is nothing more than the "words" (or chains) generated with respect to this grammar. From this point of view, natural languages and programming languages are just instances of a wider concept.
with respect to the grammar . It is nothing more than the "words" (or chains) generated with respect to this grammar. From this point of view, natural languages and programming languages are just instances of a wider concept.
A huge classification work of formal grammars has been done by Noam Chomsky [3], [4]. This author has identified four different classes.
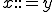 where is an arbitrary chain of symbols taken in
where is an arbitrary chain of symbols taken in 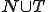 . These grammars all generate languages that can be decided by Turing machines. Equivalently, the languages they generate are recursively enumerable (see [6, Chap. 2]); as long as
. These grammars all generate languages that can be decided by Turing machines. Equivalently, the languages they generate are recursively enumerable (see [6, Chap. 2]); as long as 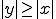 . This class contains all natural languages.
. This class contains all natural languages.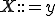 where
where 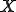 is a unique nonterminal symbol and where is an element of
is a unique nonterminal symbol and where is an element of 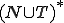 . The term can be rewritten independently from its context contrary to class 1 grammars. Subsets of class 2 grammars are commonly used to implement programming languages.
. The term can be rewritten independently from its context contrary to class 1 grammars. Subsets of class 2 grammars are commonly used to implement programming languages.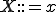 or
or 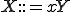 with
with 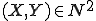 and
and 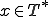 .
.In this section, we will first formalise code mutation in term of rewriting techniques. We will then be able to exhaustively address the complexity of code mutation detection according to the class of the grammar in use.
Let us consider the set of x86 instructions as our working alphabet. These instructions may be combined according to (rewriting) rules that completely define every compiler. This set of rules can be defined as a class 2 formal grammar indeed. The assembly language is then the language which is generated by this grammar.
Implementing a polymorphic engine - in particular the garbage generator which is its most important part - consists in generating a formal language, denoted polymorphic language, with its own grammar.
Let us consider a polymorphic engine generated by the grammar (the example is derived from [16]).
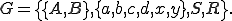
Instructions 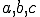 and
and 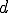 represent garbage code while instructions and are the decryptor's instructions (e.g. x=
represent garbage code while instructions and are the decryptor's instructions (e.g. x=XOR [EDI],AL,
and y=INC EDI). The rewriting system can be defined as:
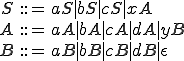
Consequently, our polymorphic language is made up of every word in the form of
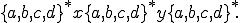
Every of these words corresponds to a mutated variant of the initial decryptor. It is thus "easy" (e.g for an antivirus software) to determine that the word abcddxd is not in this language with respect to , contrary to the word adcbxaddbydab. Other examples of less trivial polymorphic grammars are presented in [9, Chap. 6].
All this being defined, the essential issue for any antivirus is to have an algorithm which is able to determine whether a "word" (a mutated form) belongs to a polymorphic language or not. But as soon as we consider sophisticated polymorphic techniques, this ability is very difficult to evaluate. That is precisely the interest of modelling code mutation with formal grammars. According to the grammar class, we can get a more accurate insight of the detection complexity.
In order to set up our model, let us consider the following definition.
Definition 2: [12] Let be a grammar and a chain with respect to . The language decision problem with respect to consists in determining whether 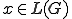 or not. The language completeness problem is that which aims at deciding whether
or not. The language completeness problem is that which aims at deciding whether 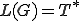 or not.
or not.
The first problem models the detection problem of polymorphism (once the relevant grammar is known). The second one models the concepts of non detection and false positive.
In order to address the detection problem, let us just recall the existing algorithmic tools we have at our disposal's. They will thus enable us to give complexity results with the different instances of this problem. A detailed description of these tools can be found in any computability handbook (e.g [12]). The generic tool is a finite automaton. Two different kinds of automata are to be considered.
We can now formalise the action of any antivirus with respect to code mutation detection. Without loss of generality, we will consider NFAs only (in fact it is possible to reduce a NFA to a DFA, up to an exponential increase of the number of states [14]).
Definition 3: [12] We say that a chain 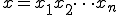 with
with 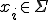 is decided by an automaton2
is decided by an automaton2 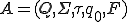 if there exist a state sequence
if there exist a state sequence 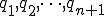 of
of 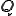 and a symbol sequence
and a symbol sequence 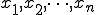 of
of 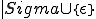 such that
such that 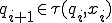 for every
for every 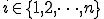 with
with 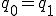 . Then we note
. Then we note 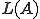 the set of any chain detected by . It is the language decided by . In other words, decides whether
the set of any chain detected by . It is the language decided by . In other words, decides whether 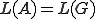 or not. Consequently, the automaton is a solution of the language decision problem with respect to the grammar .
or not. Consequently, the automaton is a solution of the language decision problem with respect to the grammar .
This definition describes the fact that as soon as an antivirus software embeds an automaton which is able to solve the (polymorphic) decision problem with respect to a given polymorphic grammar, then it is able to detect any of its "polymorphic words" (e.g mutated forms). Two critical issues are then to be considered:
The last points underlines the essential interest of metamorphic techniques compared to polymorphic ones. That is the reason why antivirus software are bound to be defeated by metamorphism. Indeed every new metamorphic mutation aims at producing a new grammar and a new word generated by the latter at the same time. Consequently, we define metamorphism as a grammar whose words are themselves a set of productions with respect to a grammar. This may be sound as a naive assumption about antivirus software. Unfortunately, it is not. It has been proved in [7], [8] that these software still heavily relies on first- or second generation scanning techniques contrary to what is claimed by the antivirus vendors.
Let us now consider our formal definition of metamorphism.
Definition 4: (Metamorphic Virus) Let 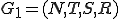 and
and 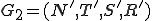 be grammars where
be grammars where 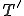 is a set of formal grammars,
is a set of formal grammars, 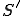 is the (starting) grammar
is the (starting) grammar 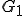 and
and 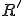 a rewriting system with respect
a rewriting system with respect 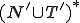 . A metamorphic virus is thus described by
. A metamorphic virus is thus described by 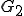 and every of its mutated form is a word in
and every of its mutated form is a word in 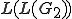 .
.
The notation which is more practical, stands for 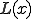 for some
for some 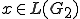 where is a grammar. This definition describes the fact that from one metamorphic form to another, the virus kernel is changing: the virus is mutating and change the mutation rules at the same time. Section IV will present a proof-of-concept of this formalisation. Definition 4 in fact somehow relates to two-level grammars (or Van
Wijngaarden grammars; 2VW grammars for short) [19], [10] in which grammar can be compared to some extent to the 2VW metagrammar. It is an open problem, at the moment, to determine whether our construction of Definition 4 is a particular case of 2VW grammars or not.
where is a grammar. This definition describes the fact that from one metamorphic form to another, the virus kernel is changing: the virus is mutating and change the mutation rules at the same time. Section IV will present a proof-of-concept of this formalisation. Definition 4 in fact somehow relates to two-level grammars (or Van
Wijngaarden grammars; 2VW grammars for short) [19], [10] in which grammar can be compared to some extent to the 2VW metagrammar. It is an open problem, at the moment, to determine whether our construction of Definition 4 is a particular case of 2VW grammars or not.
As a first consequence, managing metamorphism implies to have suitable automata at our disposal's in order to solve the language decision problem with respect to -like grammars.
We now can give complexity results for this problem, according to the existing grammar classes:
Proposition 1: The language decision problem:
Proof: This proof has been established by summarizing results given in [11], [14]. As far as class 0 grammars are concerned, we show that they generate recursively enumerable languages (their productions simulate Turing machines). Consequently, deciding whether or not for given and 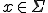 reduces the Halting problem.
reduces the Halting problem.
For class 2, the language decision problem can be solved with non deterministic pushdown automata while class 1 grammars, it is solved with linear-bounded non deterministic Turing machines. Lastly, class 3 grammars are solved by deterministic ones. Hence the results.
Proposition 1 stresses on the fact that the choice of underlying grammar is essential when designing a polymorphic engine. It has a direct impact on its resistance against its potential detection. Quite all known polymorphic engines refer to class 3 grammars. That is the reason why they can be successfully detected. But contrary to claims in [16] about systematic detection capabilities, intractability (classes 2 and 1) or even worse impossibility (class 0) rule out the practical detection when considering the cases of code mutation engines with respect to higher classes of grammars. From a practical point of view, no antivirus can monopolize computer resources for minutes or even hours to solve some rather computable instances of a NP problem. Nowadays, our saving grace is that malware writers still seem to neglect or ignore what are the "good" grammars (or the "worst" ones from the defense point of view). This statement of course only holds for already detected or detectable malware.
There exist a huge number of theoretical results in the field of formal languages [2] that can be used to build code mutation techniques that are untractable or even impossible to detect. From a general point of view, the approach consists in considering the undecidability status for some known problem. In this respect, we may consider the Rice's Theorem. Let us consider a trivial property 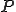 about a language; in other words, there exists at least one recursively enumerable language (class 0)
about a language; in other words, there exists at least one recursively enumerable language (class 0)  for which holds and at least one recursively enumerable language
for which holds and at least one recursively enumerable language 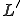 for which does not.
for which does not.
Theorem 1: (Rice's Theorem [12]) For any non trivial property with respect of languages, the problem of determining whether holds for a language 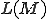 of a Turing machine
of a Turing machine 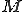 , in undecidable.
, in undecidable.
This theorem is essential since it clearly indicates in which context to look at in order to systematically defeat antivirus.
We will consider this in Section IV.
To end with formal grammars, it is worth giving the following results, whose proof will be found in [12, §10.4].
Theorem 2: Let 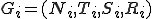 with
with 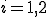 two context-free grammars. Deciding whether
two context-free grammars. Deciding whether 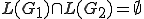 or not is an undecidable problem. Determining whether
or not is an undecidable problem. Determining whether 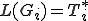 or not is undecidable as well.
or not is undecidable as well.
These two results, in the special context of context-free grammars illustrates the concepts of false positive (grammar is not a viral one while grammar indeed is a viral one) and of non detection, as far as antiviral detection is concerned [9, Chap. 2 and 4].
The word problem has been introduced and formalised by E. Post in 1950 [15]. Aside the Turing's Halting problem, it is one of the most famous problem which is known to be undecidable. This problem consists in deciding whether two finite words  and
and  over an alphabet are equivalent or not, up to a rewriting system . In other words, it consists in deciding whether
over an alphabet are equivalent or not, up to a rewriting system . In other words, it consists in deciding whether 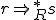 or not.
or not.
Theorem 3: [15] The word problem with respect to a semi-Thue system is undecidable.
The proof consists in reducing the word problem to the Halting problem which is itself undecidable.
Example 3: (Tzeitzin semi-Thue Systems) Let the rewriting system defined over the alphabet 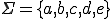 .
.

This semi-Thue system is called Tzeitsin system [18]. It is the smallest semi-Thue system which is known to be undecidable. We will denote it 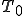 . As a consequence, any semi-Thue system which contains is itself undecidable. There exist many other undecidable Thue systems. We will use in the rest of the paper the Tzeitsin system
. As a consequence, any semi-Thue system which contains is itself undecidable. There exist many other undecidable Thue systems. We will use in the rest of the paper the Tzeitsin system 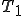 defined by:
defined by:
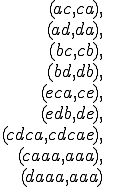
The central principle is to use formal grammars whose rewriting system is a Thue system which itself contains a Tzeitsin system or any other system which is known to be undecidable. From a general point of view, this implies that the code mutation engine based on such grammars will be undecidable as well. The core approach to design such an engine is to practically implement the concept of Definition 4. In other words, the engine's rewriting rules (namely the mutation rules) will change from mutation to mutation. For that purpose, two main constraints are to be satisfied:
contains an undecidable Thue system;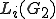 , during the i-th mutation step, contains an undecidable Thue system as well.
, during the i-th mutation step, contains an undecidable Thue system as well.From an implementation point of view, the central approach consists in coding the rewriting system of grammars as words on the alphabet 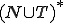 where the sets and are those of grammars
where the sets and are those of grammars 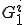 . In other words the set of rules (with respect to grammar ):
. In other words the set of rules (with respect to grammar ):
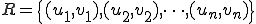
is coded as the following word:
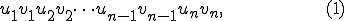
made of terminal and non terminal symbols.
The other essential point is to design a grammar which is able to manipulate such "grammar-words". The set contains words build on (Equation 1). As for the set 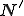 , it contains symbols which are specific to the grammar but it can also contains symbols in . The starting element is a word in
, it contains symbols which are specific to the grammar but it can also contains symbols in . The starting element is a word in 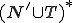 . We just have to deal with the rewriting system on words of with the constraint that
. We just have to deal with the rewriting system on words of with the constraint that 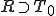 or
or 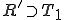 .
.
If the general principle ruling the design of grammar is simple to grasp, on the other hand its practical construction is technically far more complex. We will not present here due to lack of space - it would require tens of pages - but also not to give ready-to-use techniques that could be misused. We will give the two core principles of this practical construction only:
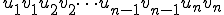 , both the order of the
, both the order of the 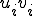 and the pairs
and the pairs 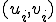 themselves at the same level;
themselves at the same level;The deep nature of the chosen rules as well as their more or less sophisticated level will have a direct impact on the detectability of the engine which embeds them.
As far as our POC_PBMOT is concerned, the MetaPHOR engine code has been considered as a starting point. The design steps are hereafter presented.
has then been built accordingly: it corresponds, up to some minor differences, to the different possible instructions;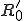 has been first designed, in such way that it includes the system. The system is a framework whose essential role is to perform code mutation itself. In other words, the rewriting takes the pairs in words into consideration. At this early stage, the set is not defined yet; of non terminal symbols in a first step. These symbols are essential since they are directly implied in the structure of the words in the form of at a macro-level. In a second step, the proto-system has been modified and tuned up in order to achieve the final rewriting system which includes the system.
has been first designed, in such way that it includes the system. The system is a framework whose essential role is to perform code mutation itself. In other words, the rewriting takes the pairs in words into consideration. At this early stage, the set is not defined yet; of non terminal symbols in a first step. These symbols are essential since they are directly implied in the structure of the words in the form of at a macro-level. In a second step, the proto-system has been modified and tuned up in order to achieve the final rewriting system which includes the system.The critical point lies in the mutation of a word in the form of
into a system
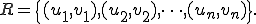
Indeed, the successive rewriting steps may induce variations of size in subwords 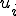 and
and 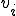 . It is thus necessary to record and update all these variations. In the same or equivalent way as the MetaPHOR engine does, the rewriting management must take the conditional or not jumps into account.
. It is thus necessary to record and update all these variations. In the same or equivalent way as the MetaPHOR engine does, the rewriting management must take the conditional or not jumps into account.
We now can state the following result.
Proposition 2: The detection of POC_PBMOT-based metamorphic codes is an undecidable problem.
Sketch of Proof.
Every mutated form 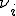 is a word in the form of
is a word in the form of
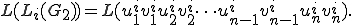
Detecting such a code consists in deciding whether two words
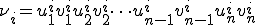
and
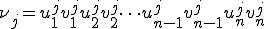
with 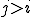 , are such that
, are such that 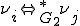 . Grammar contains and systems, which are undecidable systems. Hence the result.
. Grammar contains and systems, which are undecidable systems. Hence the result.

Remark. Proposition 2 refers to sequence based detection, in other words not in an execution context. In particular, it implies that potential successful detection is bound to consider another approach like behaviour monitoring. In this latter case, it not sure that antivirus software would be more efficient at detecting a PB_MOT-like metamorphic engine [8].
In [13], it has been suggested that metamorphic viruses are ultimately constrained in complexity. To quote the authors "...a metamorphic must be able to disassemble and reverse itself. Thus a metamorphic virus cannot utilize [...] techniques that make it harder or impossible for its code to be disassembled or reverse engineered by itself." So what about the detection of PB_MOT metamorphic codes? Two different aspects are to be considered:
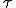 -obfuscation, a metamorphic malware can delay its own disassembly more than the antivirus can accept. While indeed ultimately constrained in complexity, any metamorphic malware can reverse engineer itself in an arbitrary time contrary to any antivirus, which is a commercial product before anything else.
-obfuscation, a metamorphic malware can delay its own disassembly more than the antivirus can accept. While indeed ultimately constrained in complexity, any metamorphic malware can reverse engineer itself in an arbitrary time contrary to any antivirus, which is a commercial product before anything else.Mutation code techniques are very efficient at practically hindering or even forbidding antiviral detection. But those techniques must be efficient enough. The theoretical approach with formal grammars is a new, promising way to systematically distinguish efficient techniques from non trivial or unefficient ones. Until now, known (theoretically detected) metamorphic codes refer to rather naive or trivial instances for which detection remains "easy".
Existing mutation code techniques, by definition, aim at preventing sequence-based detection, in a broader meaning of the term. On the other hand, some behaviours may represent useful invariant that could be considered by antivirus in the future. Consequently, the next step is likely to be behavioural polymorphism/metamorphism: code behaviours both at the micro- and the macro level would change from replication to replication. Current work in our laboratory already shows that this approach is not only powerful but also very worrying in terms of antiviral detection and protection.
It is nothing but very likely that if technical solutions to detect metamorphic codes exist, they would be non suitable for commercially-viable antivirus software. This is essentially due to the intrinsic algorithmic complexity of the detection algorithms. On the other hand, grammar-based formalisation should help antivirus programmers to identify and choose more powerful detectors to better manage existing code mutation techniques. Second generation scanners do not explore all the might of deterministic and non deterministic automata. As a consequence, existing antivirus can still be defeated by classical code mutation techniques.
1 The running environment 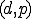 is made up of data () and programs (
is made up of data () and programs (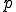 ).
).
2 The sets 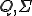 and
and 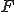 are the set of the automaton's possible states, a finite alphabet and a subset of states that can accepted by the automatom respectively. The state
are the set of the automaton's possible states, a finite alphabet and a subset of states that can accepted by the automatom respectively. The state 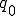 denotes the initial state whereas is the transition function
denotes the initial state whereas is the transition function 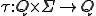 which maps a state and a symbol to a state.
which maps a state and a symbol to a state.