
Павел Семьянов
Дипломная работа, Санкт-Петербург, 1995
1995
Все прогрессивные открытия человечества рано или поздно начинали служить ему во вред. И если с момента открытия радиоактивности до создания атомной бомбы прошло ровно 50 лет, то с момента изобретения компьютера до того, казалось бы, невероятного события, что он стал применяться во зло, прошел в два раза меньший срок. Этим событием стало появление программ, направленных на нарушение функционирования отдельных компьютеров или их сети, порчу или уничтожение информации. Такие программы впоследствии получили название "вредное программное обеспечение" (badware).
Их история начинается еще с работ теоретика современных компьютеров фон Неймана. Он разрабатывал модели автоматов, способных к самовоспроизведению и математически доказал возможность существования таких машин. После этого идея саморазмножающихся программ "витала в воздухе" и время от времени находила свою более или менее адекватную реализацию.
Так, в 60-х и 70-х годах, когда в основном использовались большие ЭВМ (mainframe) типа UNIVAC, среди обслуживающего персонала существовал термин "программа-кролик" (rabbit). Так называли программу на интерпретируемом командном языке, которая запускала сама себя на выполнение, что обычно приводило систему к полному краху. Однако обычно такие программы возникали непреднамеренно, в результате ошибок программистов.
Приблизительно в 1970 г. была создана саморазмножающаяся программа для одной из первых компьютерных сетей -- APRAnet. Она называлась Creeper (вьюнок) и распространялась по сети от одного компьютера к другому. Интересно, что для уничтожения этой вредной программы была написана другая, названная Reaper (жнец), которая также распространялась по сети и уничтожала копии Creeper.
Много новых идей в развитие вредящих программ внесли писатели фантасты в 70-х годах. Например, 1975 году Джоном Брунером (John Brunner) был опубликован роман "The Shockwave Rider". В нем была достаточно детально описана программа, называемая червем (worm), которая распространялась по компьютерной сети, подбирала имена и пароли пользователей, и была распределена по всей сети -- если одни ее фрагменты уничтожались, их заменяли аналогичные, находящиеся в других компьютерах. Примерно по этой схеме был построен самый знаменитый на сегодняшний день представитель вредного ПО -- червь Роберта Морриса.
В конце 70-х годов, параллельно с появлением первых персональных компьютеров "Эпл" (Apple), стали бурно развиваться компьютерные сети, основанные на обычных телефонных каналах. Появляются первые банки свободно распространяемых программ -- BBS (Bulletin Board System, электронная доска объявлений), в которые каждый мог загрузить любую программу и считать любую из имеющихся там. Это привело к появлению первых троянских коней (Trojan Horses), которые загружались на BBS под видом полезных, а при запуске уничтожали информацию на компьютере пользователя.
Первое достоверное сообщение о появлении компьютерного вируса появилось в 1981 году. Это был вирус Elk Cloner, поражавший загрузочные сектора дискет персонального компьютера Apple II. Вирус содержал целый набор видеоэффектов -- переворачивал экран, заставлял сверкать буквы, выводил на экран стихи.
В ноябре 1983 г. доктор Фредерик Коэн (Dr. Frederick Cohen), один из первых серьезных исследователей компьютерных вирусов, продемонстрировал саморазмножающиеся программы для компьютеров VAX и системы UNIX. Коэн доказал возможность практической реализации подобных программ и их функционирования даже в защищенных операционных системах (его операционная система использовала модель безопасности Bell-LaPadula).
В 1981 г. фирма IBM выпустила свой персональный компьютер, которому суждено было стать самым массовым компьютером в истории развития вычислительной техники. Если принять во внимание, что IBM PC оснащались и оснащаются до сих пор операционной системой MS DOS, очень слабой с точки зрения безопасности, то нельзя удивляться тому, что именно "благодаря" этому компьютеру проблема вредного программного обеспечения и особенно вирусов перестала быть уделом профессионалов и обычные неподготовленные пользователи столкнулись с ней лицом к лицу. Именно десятки тысяч компьютеров IBM PC были поражены в 1987 г. при первых случаях массового заражения -- вирусами Brain и Lehigh.
Наиболее известен вызвавший всемирную сенсацию и привлекший внимание к вирусной проблеме инцидент с сетевым червем в глобальной сети Internet. Второго ноября 1988 года студент Корнелловского университета Роберт Моррис (Robert Morris) запустил на компьютере Массачусетского Технологического института программу-червь, которая передавала свой код с машины на машину, используя ошибки в операционной системе UNIX на компьютерах VAX и Sun. В течении 6 часов были поражены 6000 компьютеров, в том числе Исследовательского Института НАСА и Национальной лаборатории Лоуренса в Ливерморе -- объектов, на которых проводятся самые секретные стратегические исследования и разработки. Червь представлял собой программу из 4000 строк на языке С и входном языке командного интерпретатора системы UNIX. Следует отметить, что вирус только распространялся по сети и не совершал каких-либо вредящих действий (кроме, конечно, заметного увеличения загрузки сети). Однако это стало ясно только на этапе анализа его кода, а пока вирус распространялся, в вычислительных центрах царила настоящая паника. Тысячи компьютеров были остановлены, сеть была полностью дезорганизована, ущерб составил многие миллионы долларов.
Таким образом, можно говорить о появлении к началу 80-х годов нового класса программ, направленных на нанесение различного ущерба компьютерам, их сетям, информации, хранящейся или передающейся по ним и, следовательно, пользователям этих компьютерных систем. Именно эта функция -- нанесение ущерба или вреда и выделяется чаще всего в названии этого класса ПО. Существуют названия типа "вредящие программы", "программы-вандалы", на Западе принят термин "вредное программное обеспечение". В дальнейшем в дипломе будет применяться название "разрушающие программные средства" (РПС).
Выше уже приведены примеры почти всех видов РПС: это, прежде всего, компьютерные вирусы (computer viruses), их разновидность -- сетевые черви (worms); троянские кони (Trojan horses), и их разновидность -- программные закладки или "логические мины" (logic bombs); а также средства несанкционированного доступа.
Компьютерные вирусы и сетевые черви характеризуются в первую очередь способностью к саморепродукции. Для компьютерных вирусов это -- саморепродукция в пределах отдельного компьютера, а распространением на другие компьютеры вирус сам не занимается и предоставляет делать это человеку, копирующему программы с одной машины на другую. Для сетевого червя саморепродукция -- это именно процесс распространения с одного компьютера на другой по сети, а на одной машине иметь более одной копии ему не только не нужно, но и вредно, т.к. каждая копия отнимает дополнительные ресурсы.
Троянские кони характеризуются прежде всего функцией нанесения ущерба -- сразу после запуска или через некоторое время они уничтожают доступную информацию, форматируют жесткие диски, портят конфигурацию компьютера и т.п. Обычно они маскируются под игровые или развлекательные программы и делают это под красивые картинки или музыку. Программные закладки также содержат некоторую функцию, не оговоренную в спецификации, но эта функция, наоборот, старается быть как можно незаметнее, т.к. чем дольше программа не будет вызывать подозрений, тем дольше эта функция-закладка сможет работать. Примерами последних РПС могут быть: широко известная программа, осуществляющая атаку "салями" --зачисление остатков денег при округлении на определенный счет; программа, посылающая информацию о состоянии дел в конкурирующей фирме; закладка, внедренная в ПО военного комплекса, блокирующая его в некоторый момент по радиосигналу и т.п.
У средств несанкционированного доступа главной особенностью является способность к "проникновению" в защищенную компьютерную систему через ошибки или "дыры" в соответствующих системах безопасности или администрирования, а также "в лоб" -- путем перебора или криптографической дешифровки паролей.
Естественно, что с появлением первых РПС (в основном, вирусов) не могли не появиться программные средства зашиты от них. (Подробнее они будут рассмотрены в главе 1). И пока число РПС исчислялось единицами или десятками, ситуация была терпимой и средства защиты более или менее справлялись с ними.
К сожалению, в скором времени, начиная с конца 1990 г., проявилась новая тенденция, получившая название "экспоненциальный вирусный взрыв". Количество новых вирусов, обнаруживаемых в месяц, стало исчисляться десятками, а в дальнейшем и сотнями. Поначалу эпицентром этого взрыва была Болгария, затем он переместился в Россию. Данные о количестве известных вирусов в операционной системы MS DOS по годам приведены на рис 1.
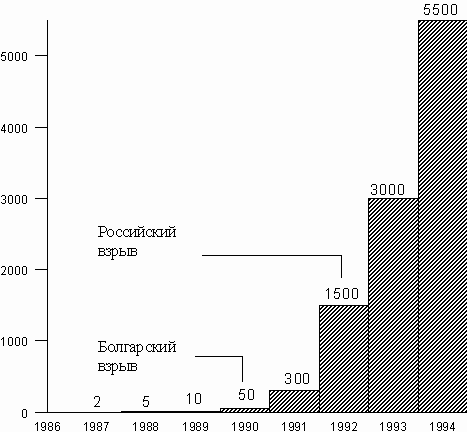
Рис. 1. Компьютерные вирусы в MS DOS на конец года, шт.
Этот процесс нарастания количества компьютерных вирусов можно разделить на три этапа, каждый из которых имеет свои причины. Это т.н. "болгарский вирусный взрыв", "российский вирусный взрыв" и современная ситуация.
Болгарский взрыв, произошедший в 1990 г., обязан группе болгарских хакеров, поставивших своей целью выпускать не просто новые вирусы, а целые семейства, постепенно их модифицируя и делая все более опасными и неуязвимыми. Так как до 1990 г. количество всех вирусов исчислялось единицами, то появление в короткое время около полусотни новых и получило название "взрыва" [1]. Наиболее известными представителями этих вирусов были семейства Yankee Doodle и Dark Avenger. Очень многие идеи, реализованные в этих вирусах, до сих пор находят свое применение и продолжение. Почему это произошло в Болгарии? Очевидно, это была первая страна социалистического лагеря (соответственно, отсутствовали охрана авторского права на программы и ответственность за их несанкционированное копирование, что приводило к тому, что 99% ПО приобреталось незаконно, а это делало распространение вирусов с ним очень легким), начавшая серийно выпускать IBM PC-совместимые компьютеры.
Российский взрыв был тоже вполне закономерен и предсказан, в частности автором, еще в 1990 г. [2]. Повальная компьютеризация СССР, введение в школах преподавания информатики, подогревающая нестабильная ситуация в стране, такое же, как и в Болгарии, отсутствие законов об охране авторского права -- все это причины этого явления.
Примерно с середины 1992 года существует такое явление, как компьютерный андерграунд, специализирующийся на вскрытии систем защиты, нелегальном копировании и т. д. В условиях тотальной компьютеризации и наличия глобальных и локальных сетей компьютерный андерграунд объединяет хакеров (hackers) со всего мира. Существует даже регулярный электронный журнал "40Hex", публикующий исходные тексты вирусов, алгоритмы распространения, способы преодоления систем защиты и борьбы с антивирусными средствами и т. д. Имеется (в том числе у в России) немало BBS, распространяющих как сами вирусы, так и их исходные тексты и другую информацию. Естественно, что при желании воспользоваться этой информацией может кто угодно.
Наконец, современная ситуация внесла еще больше драматизма в создавшееся положение. Она характеризуется двумя моментами: появлением полиморфных вирусов и генераторов (конструкторов) вирусов.
Полиморфные вирусы характеризуются тем, что для их обнаружения неприменимы обычные алгоритмы поиска, так как каждая новая копия вируса не имеет со своим родителем ничего общего. Это достигается шифровкой тела самого вируса и расшифровщиком, не имеющим ни одного постоянного бита в каждом своем экземпляре. На сегодняшний день известно около десятка алгоритмов (не вирусов, их намного больше!) генерации таких расшифровщиков. Обычно они оформлены в виде объектного файла, и каждый, кто хочет превратить свой вирус в полиморфный, может просто присоединить этот файл к объектному файлу вируса.
Появление генераторов вирусов избавляет самых ленивых авторов от необходимости программировать свой вирус -- зачем утруждать себя, если можно в меню задать способ распространения, тип, вызываемые эффекты, причиняемый вред и получить ассемблерный текст нового вируса. На сегодняшний день известно около пяти таких генераторов вирусов.
Таким образом, экспоненциальный рост количества вирусов привел к тому, что средства защиты просто не успевают за развитием ситуации и выходят в свет с запозданием. Если вы сегодня пользуетесь программой месячной давности -- она может вас только сбить с толку, убедив, что ваш компьютер свободен от вирусов. На самом деле он может быть заражен десятком новых, которых антивирусная программа просто не знает. А менять копию программы каждую неделю не только утомительно пользователю, но и автору приходится днями и ночами заниматься тем, чтобы исследовать все новые и новые вирусы, хотя очевидно, что в этой гонке он уже проиграл.
Итак, в настоящее время особенно актуальна стала задача поиска неизвестных вирусов (и других РПС) в программном обеспечении, которое, как правило, поступает в виде исполняемого кода. И хотя эта задача уже исследовалась раньше, удовлетворительного решения до сих пор нет.
На сегодняшний день большинство существующих программных средств борьбы предназначено для защиты только от одного (самого распространенного) класса РПС - компьютерных вирусов. Только сторожа пытаются бороться также и с троянскими конями. Программ, призванных служить для защиты от других классов РПС, в настоящее время просто нет. Поэтому в этой главе далее будут рассмотрены в основном различные классы антивирусных средств. Предполагается, что читатель имеет некоторое представление (хотя бы из введения) о том, что такое компьютерные вирусы, а подробнее на их определении мы остановимся в следующей главе.
Основная задача всех антивирусных средств -- обнаружить (или не дать возможность размножаться) вирусу в системе с максимальной степенью надежности, то есть избежать ошибок первого рода (необнаружения вируса, хотя на самом деле он присутствует) и второго рода -- т.н. "ложных тревог" (обнаружения вируса там, где на самом деле его нет).
Наиболее простой и очевидный класс антивирусных средств, являвшийся основным до недавнего времени. Борьба ведется только с известными вирусами. Детекторы только обнаруживают их в системе, а фаги также "вылечивают" зараженные объекты.
Это группа средств достаточно распространена и основана на сканировании памяти, файлов на внешних носителях, загрузочных записей и других объектов, могущих получить управление (чтобы вирус имел возможность исполняться), с целью обнаружения известных и изученных автором антивирусной программы типов вирусов. В связи с вирусным взрывом (см. п. 0.3) важнейшей характеристикой таких программ является возможность оперативного добавления новых типов вирусов в очередных версиях программы.
Хорошо зарекомендовавшие себя, насчитывающие десятки версий программы этого класса практически не подвержены ошибкам второго рода -- если такая программа сообщила о зараженных файлах, то можно быть уверенным, что это действительно так. Однако, если детектор не нашел вирусов в системе, это означает только одно: в системе нет вирусов, на которые он рассчитан, ведь против остальных он бессилен.
Имеется два алгоритма поиска вирусов в исполняемых файлах.
Первый связан с поиском сигнатур или регулярных выражений.
Сигнатурой вируса называется последовательность байтов,
Однако истинность условия б) невозможно проверить на практике, поэтому для уменьшения вероятности ложных срабатываний необходимо использовать сигнатуры как можно большей длины. (Скорость хорошего алгоритма поиска подпоследовательности только возрастает с увеличением ее длины). Идеальным с точки зрения теории представляется вариант, когда сигнатура совпадает с самим телом вируса, при этом условия а) и б) выполняются автоматически. К сожалению, такой вариант существует на практике чрезвычайно редко, но сигнатуры длиной до 90% от длины вируса для вирусов простой структуры выделить можно. На практике детекторы используют в качестве сигнатуры характерный для этого вируса фрагмент кода (например, из обработчика прерывания) длиной в несколько десятков байт (при средней длине вируса 2-3 Кбайта), что, конечно, ставит истинность условия б) под вопрос.
Таким образом, принцип работы таких детекторов очень прост -- если в каком-либо объекте обнаружена сигнатура, то он считается зараженным. Следует не забывать, что в последнее время появились вирусы, не поддающиеся обнаружению ни с помощью обычных, ни с помощью регулярных сигнатур (подробнее см. п. 3.2.1).
Второй алгоритм -- это проверка кода программ. Проверяется область программы, получающая управление в начале, на предмет совпадения с командами вируса, настроенного на данный файл. Например, наличие перехода на определенное смещение от конца программы. Т.о. можно сказать, что в качестве "сигнатуры" (назовем ее структурной) здесь выступает не последовательность байт, а способ имплантации вируса в зараженную программу. В этом случае условие б) выполняться будет достаточно редко, т.к. существует немного способов внедрения вируса в программу, и этот алгоритм будет подвержен также ошибкам и второго рода.
Понятие структурной сигнатуры эффективно применяется и является единственным быстрым критерием при поиске полиморфных вирусов. Под структурной сигнатурой здесь понимается структура алгоритма, т.е. последовательность команд передачи управления и образующиеся при этом ветвления, циклы, вызовы подпрограмм. Недоработка MtE-алгоритма, а именно "предсказуемость" цикла расшифровки, позволила создать MtE-детекторы, не требующие интерпретации кода программ.
На практике применяется сочетание двух методов -- сначала программа проверяется вторым алгоритмом (более быстрым), и лишь в случае нахождения структурной сигнатуры используется первый.
Фаги отличаются от детекторов только тем, что кроме обнаружения вирусов они восстанавливают, если возможно, зараженные области, удаляя из них вирусы. Для процесса восстановления необходимо тщательно изучить алгоритм заражения, чтобы совершить обратные действия. В абсолютном большинстве случаев это оказывается возможным (это следует из того, что вирус должен распространяться, поэтому он сохраняет работоспособность зараженного объекта), хотя необходимо помнить, что речь идет только о восстановлении исполняемого кода, а не о ликвидации всех последствий деструктивных действий вируса.
Наиболее известными программами данного типа для операционной системы MS DOS являются программы Aidstest Д. Н. Лозинского, Scan/Clean фирмы McAfee Associates, Microsoft AntiVirus фирмы Central Point Software, входящий в дистрибутив MS DOS 6.0.
В табл. 1.1 представлена информация о количестве вирусов, обнаруживаемых известными фагами на конец 1994 г.
| Программа | Число обнаруживаемых вирусов |
|---|---|
| Aidstest | 1058 |
| Scan/Clean | 2738 |
| Microsoft Antivirus | более 1000 |
Табл. 1.1. Количество обнаруживаемых вирусов программами-детекторами для MS DOS на конец 1994 г.
Однако надежного способа закрыть их без аппаратной поддержки не существует. Пакеты такого типа подвержены ошибкам как первого, так и второго рода. Как показывает практика, подобные программы доставляют большие неудобства пользователям, надоедая навязчивыми сообщениями типа "Разрешать запись в такой-то файл? <Да/Нет>", бесполезными почти во всех случаях. Известны попытки создания интеллектуальных сторожей, пытающихся различать ложные и настоящие тревоги, однако это неизбежно ведет к снижению их надежности.
Несомненным достоинством сторожей является их уникальная способность блокировать РПС в момент попытки нанесения ими ущерба. Таким образом, сторожа защищают не только от вирусов, но и от троянских коней.
Наиболее известными программами этого класса для IBM PC являются пакет Flu-shot+ и антивирусный монитор -D Е.Касперского. Сравнительный анализ функций этих программ приведен в табл. 1.2.
| Функция | Flu-Shot+ | -D |
|---|---|---|
| Изменение или переименование СОМ, ЕХЕ и SYS -файлов | + | + |
| Оставление резидента | + | + |
| Уменьшение размера свободной памяти DOS | - | + |
| Уменьшение размера системных буферов | + | + |
| Запись на диск по абсолютному адресу | + | + |
| Форматирование диска | + | + |
| Запись в MBR или BOOT-сектор | + | + |
| Вызов нестандартных функций DOS | - | + |
Табл. 1.2. Сравнительный анализ сторожей для MS DOS.
Программы этой группы основаны на сравнении контрольной информации о файлах, файловой системе, загрузочных областях и других элементах вычислительной среды с текущим их состоянием с целью обнаружения изменений, производимых вирусами, и локализации зараженных или поврежденных объектов. Осуществляется это очень просто -- ревизор сначала сохраняет эталонную информацию (в виде контрольных сумм, например) об этих элементах, а впоследствии проверяет соответствие начальных и текущих значений.
Неоспоримым преимуществом ревизоров является их устойчивость к ошибкам первого рода: если ревизор сообщает, что объект изменился, значит, это действительно так. Правда, они подвержены ошибкам второго рода -- ревизор не в состоянии определить, в результате чего изменилась программа -- потому что ее поразил вирус, или ее просто перетранслировали. Неудобство таких программ заключается в необходимости периодического сканирования вычислительной среды и большом числе ложных тревог. В связи с "вирусным взрывом" (см. введение) программы-ревизоры становятся единственным классом антивирусных средств, гарантирующих пользователю хоть какую-то безопасность.
Наиболее известная программа этого класса -- Adinf Д. Мостового.
В то время, когда аналогия между компьютерными вирусами и их биологическими собратьями просматривалась очень четко (отсюда и произошла все современная терминология, включая само слово "вирус"), большие надежды возлагались на самые перспективные средства защиты от биологических вирусов -- вакцины. Они призваны создать такие условия для вируса (компьютерного или биологического), делающее его размножение невозможным.
Подавляющее большинство компьютерных вирусов проверяют возможность заражения объекта -- хватит ли памяти, не имеется ли там уже копия вируса и т.п. Поэтому задача вакцины -- изменить этот объект или вычислительную среду так, чтобы условие возможности заражения стало ложным.
Для вакцин можно с некоторой натяжкой говорить об ошибках первого рода (маловероятно, что вакцина не сработает против того, чего должна), но нет никакого смысла обсуждать ошибки второго рода.
Успешно вакцины можно применять тогда, когда способ заражения объекта не может сильно варьироваться (в связи со свойствами самого объекта). Для MS DOS такими объектами служат BOOT-сектора и MBR, и в последнее время они с успехом вакцинируются, в т.ч. на уровне BIOS.
На сегодняшний день нет вакцин (вернее было бы сказать -- уже нет вакцин) в MS DOS для файлов, но они должны появиться в других операционных системах как их компонент, затрудняющий распространение вирусов.
К этой группе относятся следующие средства:
Результаты этого анализа приведены в табл. 1.3. Она подтверждает, что самыми совершенными на сегодняшний день являются ревизоры, самыми неудачными -- вакцины, а перспективные средства (в перспективе) должны были бы превосходить любое из представленных.
| Характеристика | Детекторы | Фаги | Сторожа | Ревизоры | Вакцины | Перспективн. | Коэф. значим. |
|---|---|---|---|---|---|---|---|
| Обнаружение/ неразмножение известных вирусов | + | + | + | + | + | + | 8 |
| Лечение известных вирусов | - | + | - | +/- | ? | + | 4 |
| Обнаружение/не размножение неизвестных вирусов | - | - | + | + | - | + | 16 |
| Лечение неизвестных вирусов | - | - | - | +/- | - | +/- | 4 |
| Возможность борьбы с большим количеством вирусов | + | + | + | + | - | + | 8 |
| Количество обнаруживаемых типов вирусов | С | С | С | В | Н | В | 12 |
| Надежность (отсутствие ошибок первого рода) | В | В | С | В | В | С | 6 |
| Адекватность (отсутствие ошибок второго рода) | В | В | Н | Н | ? | С | 4 |
| Нетребовательность к ресурсам (памяти, времени) | В | В | С | Н | Н | Н | 4 |
| Взвешенная оценка, балл | 4.0 | 4.4 | 4.8 | 6.0 | 2.0 | 6.1 | 7.3 |
Табл. 1.3. Сравнительная характеристика антивирусных средств для операционной системы MS DOS.
Символы означают:
Рассмотрим теперь недостатки перечисленных групп средств применительно к сегодняшней ситуации с компьютерными вирусами. Как указывалось во введении, она характеризуется двумя тенденциями -- соответственно, антивирусным средствам приходится решать две проблемы:
Недостатки детекторов и фагов вытекают из их основной характеристики, что они могут бороться только с известными им вирусами. В последнее время появились программы, не требующие для обновления версии получения новой программы, а использующие открытую и постоянно пополняемую (в т.ч. и самим пользователем) базу данных. Но это, конечно, нельзя назвать решением проблемы 1. Более того, проблема 2 также оказывается непосильной для детекторов -- вирусы с само модифицирующимся расшифровщиком не могут быть обнаружены простым сигнатурным поиском. Эта проблема вроде бы успешно решалась до последнего времени введением понятия "регулярная сигнатура" (см. п. 3.2.1), но после появления полиморфных вирусов такие сигнатуры оказались также непригодны для детектирования зараженных объектов.
Все вышесказанное относится и к вакцинам, которые оказываются еще более худшим антивирусным средством. Дело в том, что защита даже от нескольких известных вирусов с помощью них невозможная. Вакцинация от десятка вирусов приведет к тому, что вычислительная среда будет настолько сильна изменена (появятся новые обработчики прерываний, все файлы будут сильно искажены), что компьютерная система будет работать неустойчиво или не будет работать вовсе. О каких тысячах вирусов может тогда вестись речь! Также нетрудно представить себе 2 вируса, использующие такие условия возможности заражения, что ложность первого из них эквивалентна истинности второго, и поэтому вакцинация от обоих этих вирусов сразу просто невозможна. (Например, пусть один гипотетический вирус заражает только файлы длиной больше 32K, а другой -- только меньше).
Рассмотрим далее классы антивирусных средств, вроде бы направленных на борьбу с неизвестными вирусами.
Сторожам в принципе все равно, известный или новый вирус пытается отформатировать жесткий диск. Но! Только если он пытается сделать это каким-то предусмотренным автором антивируса способом. Таким образом, проблема 2 -- появление новых вирусных идей остается для сторожей открытой. Ну и большое неудобство, что на очень многие полезные программы сторож будет "ругаться", доводя пользователя до исступления.
Ревизоры, как уже подчеркивались, являются на сегодняшний день наиболее надежным и дающим хоть какую-то гарантию антивирусным средством. В частности, с проблемой 1 они прекрасно справляются. Но они также имеют несколько существенных недостатков. Первый очевиден -- если в момент установки ревизора в компьютерную систему там уже присутствовал вирус, он это никак не обнаружит ни при установке, ни в дальнейшем (если вирус будет достаточно аккуратен), вплоть до часа Х, когда присутствие вируса в системе уже будет понятно и без ревизора. Проблема 2 дает себя знать во втором недостатке -- если вирус применяет какую-то новую идею по внедрению в компьютерную систему, неизвестную ревизору, он не будет обнаружен. И наконец, информация, сформированная ревизором, в 99% случаев потенциально доступна любой программе, а, значит, и вирусу, который может ее исказить так, что ревизор не будет реагировать на его внедрение; или просто уничтожить, в результате чего ревизор вынужден будет собирать всю информацию заново при наличии активного вируса в системе!
Таким образом, мы видим, что ни одно из существующих антивирусных средств не справляется в полной мере с современной ситуацией, а средств зашиты от других РПС (кроме вирусов и троянский коней) на сегодняшний день вообще нет.
Итак, мы видим, что для концепции открытых компьютерных систем (когда входные и выходные потоки информации ничем и никем не контролируются) нет удовлетворительного решения проблемы защиты от РПС. С другой стороны, если в полностью зарытой (изолированной) компьютерной системе изначально нет РПС, то они никогда не смогут появиться в ней. (Не будем рассматривать ситуацию, когда РПС создаются внутри этой системы -- во-первых, это больше организационная проблема, а во-вторых, в этом случае такую компьютерную систему можно рассматривать как совокупность маленьких изолированных, к каждой из которых применимы данные рассуждения).
Однако концепция полностью закрытой системы вряд ли сможет стать жизнеспособной (кроме разве что военных, секретных и т.п. систем -- но даже в этом случае то программное обеспечение, функционирующее внутри, должно быть сертифицировано, в т.ч. и на предмет отсутствия РПС). Поэтому была сформулирована идея "полуоткрытой" (или "полузакрытой", если вы пессимист) компьютерной системы, иначе "шлюзовой" системы [13] (см. рис. 1.1). В ней предполагается контроль всей поступающей информации на предмет наличия в ней РПС. Естественно, что РПС должны находиться в информации, подлежащей исполнению, т.е. в программном коде (на любом языке). Проблема сертификации программного обеспечения на языке высокого уровня является трудной, но в достаточной степени исследованной и здесь рассматриваться не будет.
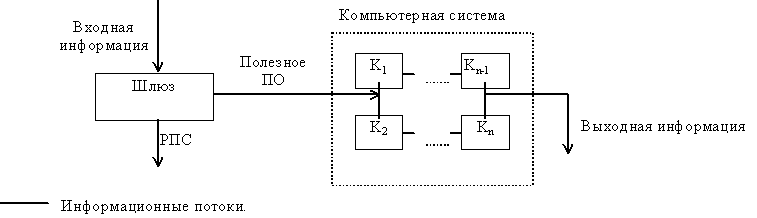
Рис. 1.1. Схема шлюзовой компьютерной системы
Поэтому задачу, которую хотелось бы решить, можно сформулировать как поиск РПС (в т.ч. и неизвестных заранее) в исполняемом программном коде.
Она разбивается на ряд подзадач:
Организация эффективной системы борьбы с различными видами РПС невозможна без разработки формализованной модели, описывающей их структуру и принципы функционирования. Наличие такой модели позволит создать универсальные средства противодействия, повысить их эффективность и определить область применения. Кроме того, такая модель может быть использована для определения условий распространения РПС (в частности, компьютерных вирусов), а также и для построения различных средств противодействия их распространению.
Основные работы, которые касаются данной предметной области, можно условно отнести к трем направлениям:
Последний подход, по мнению автора, выглядит наиболее перспективным, поскольку позволяет получить практические решения для задач поиска, обнаружения и ликвидации всех классов РПС, а не только компьютерных вирусов. Чтобы убедиться в правомерности такого предположения, рассмотрим ситуацию с компьютерными вирусами с точки зрения работ первого направления.
Совершенно очевидно, что основным свойством вируса, с помощью которого его и надо определять, является способность к саморепродукции (репликации), т.е. к размножению и порождению себе подобных. Однако оказывается, что строго это сделать не так просто, в частности, для этого необходимо иметь формальное определение "саморепродукции" в компьютерных системах. Попытка уйти от этого делается в классическом определении вируса.
Оно остается неизменным с 1984 г., когда оно было дано Ф.Коэном в своей основополагающей работе [9] и звучит как: "компьютерный вирус -- это программа, которая может заражать другие программы, изменяя их посредством добавления своей, возможно модифицированной, копии, которая сохраняет способность к дальнейшему размножению".
Как мы видим, Ф. Коэн уходит от понятия "саморепродукция" изменяет его производным -- "заражение" (раз вирус должен размножаться, то в результате этого некоторые объекты должны приобрести копию вируса, т.е. заразиться), считая его определяющим свойством вируса.
При внимательном разборе этого определения сразу возникает ряд вопросов:
Неоднократно делались попытки улучшить это определение. Одна из таких последних попыток принадлежит П. Петерсону (P. Peterson) в редакции Б. Себорга (B. Seborg) [16], которые определяют компьютерный вирус как "саморепродуцирующуюся программу, которая может заражать другие программы, модифицируя их или их среду (environment) так, что запуск (call) зараженной программы приводит к запуску возможно претерпевшей эволюцию (evolved) и в большинстве случаев функционально подобной копии вируса".
Это попытка закрыть первые три дыры в определении Коэна, но при этом появляются другие неопределенные понятия: "копия, претерпевшая эволюцию", "функционально подобная копия", которые еще и рассматриваются только в "большинстве случаев".
Ф. Коэн, основываясь на своем определении, строго доказывает, что обнаруживать вирусы, используя только их основное свойство -- заражение, невозможно.
Чтобы определить, что данная программа P является вирусом, должно быть установлено, что P заражает другие программы. Пусть D -- это гипотетическая функция, которая возвращает значения "истина" тогда и только тогда, когда ее аргумент является вирусом. Тогда P сама может использовать эту функцию D и заражать другие программы только тогда, когда D(P) возвращает "ложь" (см. прог. 1).
VIRUS CV
{
VIRUS; // Признак наличия вируса в программе для повторного
// ее незаражения
если не D (CV) то
{
ЗАРАЗИТЬ_ПРОГРАММУ;
если УСЛОВИЕ_СРАБАТЫВАНИЯ то МАНИПУЛЯЦИИ;
}
передать управление зараженной программе;
}
Прог. 1.Вирус с противоречием.
Если процедура D принятия решения определяет, что CV -- это вирус, то CV не будет заражать другие программы и не будет таким образом вирусом по определению. Если D определяет, что CV -- не вирус, то CV будет заражать другие программы и поэтому будет вирусом. Отсюда следует, что процедура принятия решения D противоречива и создать ее невозможно. Таким образом, универсального антивируса не существует и точное обнаружение вируса без его запуска является неразрешимой задачей.
Не является ли тогда бессмысленными после приведенного доказательства все дальнейшие рассуждения (ведь мы строим, в принципе, универсальную программу, определяющий принадлежность входной программы к РПС)? Более того, какое бы формальное определение вируса мы не дали (например, "вирус -- это программа, наносящая вред" или даже "вирус -- это программа, выводящая "Hello, world"), всегда можно построить программу, аналогичную приведенной выше, чтобы убедиться в невозможности построения той злополучной функции D.
Вывод: надо искать в другой плоскости.
Очень заманчивым с точки зрения формализации кажется следующее определение вируса: "вирус -- это программа, способная порождать другие вирусы". Увы, оно рекурсивно неразрешимо: нет условия окончания рекурсии.
Тут мы сталкиваемся с почти философской проблемой -- как определить объекты, ключевым свойством которых является порождение себе подобных, причем подобие определяется с помощью того же свойства -- порождать себе подобных и т. д.
Попытаемся дать более точное рекурсивное определение вируса. Во-первых, очень легко можно решить проблему простых мутаций вируса, если мы будем говорить, что понимаем под вирусом не программу, а алгоритм, число возможных реализаций которого на конкретном языке может быть любым. Тогда любые простые мутации вируса будут эквивалентны друг другу по своему алгоритму и простой мутирующий вирус можно определить как "алгоритм, который может порождать эквивалентный ему алгоритм и обеспечивать возможность получения им управления".
Во-вторых, что касается эволюционных мутаций, то здесь, наоборот, порождаются совершенно не эквивалентные по алгоритму вирусы.
Очень интересным здесь является вопрос о существовании алгоритмов, способных порождать бесконечное количество неэквивалентных алгоритмов. Например, пусть каждая новая копия вируса сдвигает срок своего проявления на один день. Таким образом, казалось бы, мы получим бесконечное число различных вирусов. Но это не так, потому что данные, где хранится дата проявления, имеют фиксированный размер, и рано или поздно произойдет переполнение. Размер данных не может увеличиваться до бесконечности, т.е. длина вируса тоже имеет ограничение, иначе, если длина каждой новой копии увеличивается, то однажды ему не хватит памяти для записи новой копии и таким образом будет нарушена способность к дальнейшему порождению. Эти, правда, не очень строгие рассуждения позволяют сделать заключение, что бесконечно неповторяющегося мутирующего вируса быть не может, и рекурсия заканчивается либо на повторении, либо на порождении алгоритма, неспособного к дальнейшему размножению.
Заметим также, что термин "порождать", хотя он не может быть строго определен, означает именно процесс рождения "из ничего", без всяких входных данных, иначе очень много обычных программ попали бы под определение вируса (например, транслятор, "порождающий" исполняемый код из исходного).
Тогда полное определение компьютерного вируса может звучать так: "Компьютерный вирус (саморепродуцирующийся алгоритм) -- это алгоритм, который может порождать без использования входных данных:
Vi -- комп. вирус, если он порождает Vi+1 , где
б) Vi+1 -- алгоритм | $ j, j=1..i, Vi ~ Vj
в) Vi+1 -- комп. вирус | " j, j=1..i, Vi !~ Vj
Однако, как было показано (см. п. 2.1.2), и это свойство -- порождение других алгоритмов -- нельзя использовать для обнаружения компьютерных вирусов по внешнему виду. Поэтому мы перейдем к рассмотрению моделей и определений, пригодных с практической точки зрения.
Наиболее приближенным к практике является подход, представляющий РПС в виде системы концептов (понятий) на функциональном уровне. Хотя он и не позволяет получить результаты столь глобального характера, как при математическом моделировании, но с точки зрения создания теоретических основ поиска РПС появляются возможности: во-первых, создать обобщенную концептуальную модель РПС для структурирования знаний по РПС и выбора способа их представления; во-вторых, реализовать целенаправленный поиск функциональных элементов РПС в прикладных программах; в-третьих, решить задачу создания структурно-алгоритмического образа РПС. Тем самым становится возможным переход к построению программной модели (синтезу) РПС для исследования механизмов его работы.
При введении понятия РПС было замечено, что наиболее важной их характеристикой является способность к нанесению ущерба компьютерной системе. Однако важно отметить, что такую характеристику не так просто конкретизировать и сопоставить ей конкретные признаки. Связано это с двумя причинами: во-первых, любая прикладная программа, заведомо не относящаяся к числу РПС, потенциально может содержать в себе алгоритмические ошибки, проявление которых приведет к разрушению элементов вычислительной среды. Во-вторых, злоумышленник-пользователь может нанести ущерб элементам операционной или вычислительной среды, используя штатное программное обеспечение (системные или сервисные программы ОС), превращая его в РПС.
Таким образом, мы получаем первый функциональный элемент, часто встречающийся в РПС -- процедуру нанесения ущерба (ПНУ, другие названия: нарушения целостности, нападения, разрушения), под результатом действия которой будем понимать нанесение ущерба компонентам вычислительной среды.
Не менее значимым для РПС является наличие еще двух элементов: процедуры саморепродукции (ПСР) и процедуры преодоления защиты (ППЗ), также являющиеся "вредными", т.е. не встречающиеся в "хороших" программах.
Как показано в п. 2.1, точного определения понятия саморепродукции по отношению к программам не существует. По аналогии с биологическими системами мы будем понимать под свойством саморепродукции способность к порождению некоторого программного кода. Это несколько расширяет приведенное рекурсивное определение саморепродуцирующегося алгоритма, но для практического применения является пригодным).
Под процедурой преодоления защиты понимается попытка преодоления системной и/или дополнительной защиты. Системной защитой будем называть систему безопасности, являющуюся частью ОС (система разделения пользователей, защита доступа к файлам, защита ядра ОС). Под дополнительной защитой понимаются все компоненты системы безопасности, не являющиеся частью ОС (обычно это системы криптографической защиты и т. д.). Факт преодоления системы защиты означает осуществление действий, запрещаемых системой защиты (получение неавторизованного доступ, подбор пароля и т. д.).
Тогда на основе этих трех элементов можно дать функциональное определение РПС: под РПС будем понимать программный код, реализующий одну из этих процедур.
Далее можно сформулировать условия необходимости и достаточности, позволяющее провести классификацию РПС по трем основным классам (иллюстрация на рис. 3):
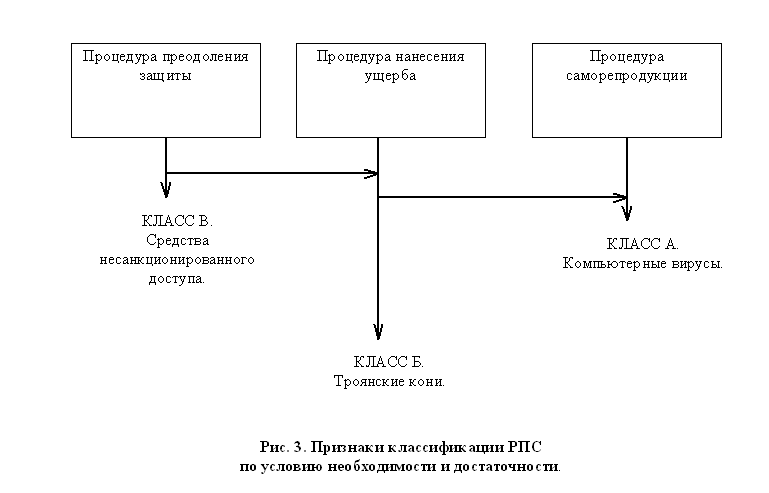
Рис. 3 Признаки классификации РПС по условию необходимости и достаточности
Приведенная классификация является единой формализованной формой представления различных видов РПС. Более того, такое представление не только не противоречит основному принципу современной технологии программирования -- принципу модульности, -- когда программа строится в виде совокупности процедур, но и хорошо согласуясь с ним, дает некоторую базу для создания методик поиска РПС (или элементов РПС) в исполняемых кодах программ, основанных на такой концептуальной модели РПС.
Введя дополнительный набор возможных функциональных элементов РПС: процедуру захвата управления, процедуру мутации, процедуру синтеза, процедуру шифровки и т.п., можно построить обобщенную концептуальную модель (рис. 4) в виде совокупности его функциональных элементов. Обобщенная модель отражает возможную структуру трех основных классов РПС.
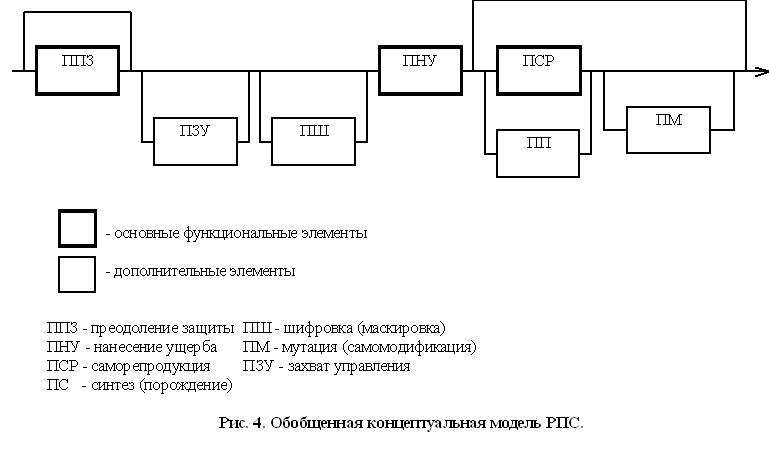
Рис. 4. Обобщенная концептуальная модель РПС
Учитывая введенные три основные функции, присущие РПС, получаем 8 различных их комбинаций, т.е. видов РПС (9-ая не является РПС). В зависимости от того, какой признак мы будем рассматривать в качестве базового, можно построить три возможных классификаций РПС (табл. 4, 5, 6).
| Признак | Классификация | ||||||
|---|---|---|---|---|---|---|---|
| Вирусы | Средства НСД | Тр. кони | |||||
| безопасные | проникающие | разрушающие | разрушающие и проникающие | ||||
| Саморепродукция | X | X | X | X | |||
| Преодоление защиты | X | X | X | X | |||
| Нанесение ущерба | X | X | X | X | |||
Таблица 4. Классификация РПС на база вирусов
| Признак | Классификация | ||||||
|---|---|---|---|---|---|---|---|
| Средства НСД | Вирусы | Тр. кони | |||||
| проникающие | самораспространяющиеся | разрушающие | разрушающие и самораспространяющиеся | ||||
| Саморепродукция | X | X | X | X | |||
| Преодоление защиты | X | X | X | X | |||
| Нанесение ущерба | X | X | X | X | |||
Таблица 5. Классификация РПС на базе средств НСД
| Признак | Классификация | ||||||
|---|---|---|---|---|---|---|---|
| Троянские кони | Вирусы | Ср. НСД | |||||
| простые | самораспространяющиеся | проникающие | самораспространяющиеся и проникающие | ||||
| Саморепродукция | X | X | X | X | |||
| Преодоление защиты | X | X | X | X | |||
| Нанесение ущерба | X | X | X | X | |||
Таблица 6. Классификация РПС на базе троянских коней
Наконец, можно классифицировать все известные виды РПС по предлагаемым признакам (табл. 7). Как видно, различий между троянскими конями и программными закладками здесь нет, что вполне естественно, т.к. как-то конкретизировать функции, присущие только программным закладкам, чрезвычайно трудно.
Итак, для определения принадлежности программы к РПС нам достаточно найти в ее составе одну из процедур: саморепродукции, нанесения ущерба, преодоления защиты. Чтобы определить, что данная процедура принадлежит к числу искомых, необходимо проанализировать ее семантический смысл, т.е. понять алгоритм.
Таким образом, задача, поставленная в главе 1, может быть конкретизирована как семантический анализ исполняемого кода программ на предмет наличия заданной функции.
Поэтому пора рассмотреть методы анализа исполняемого кода, что и будет сделано в следующей главе.
При анализе программ на любом языке обязательно присутствуют три этапа (цифры соответствуют рис. 5 и рис. 8):
Первые два из них обычно осуществляются автоматически (например, компиляторами), а семантику отслеживает человек. В этой главе мы попытаемся применить эту схему и к анализу программ в исполняемом коде, хотя точной аналогии между понятиями, существующими в теории компиляторов и вводимыми здесь, провести нельзя.
Каждый из этих этапов также требует предварительной подготовки:
Таким образом, общая поэтапная схема анализа программ будет выглядеть так (рис. 5):
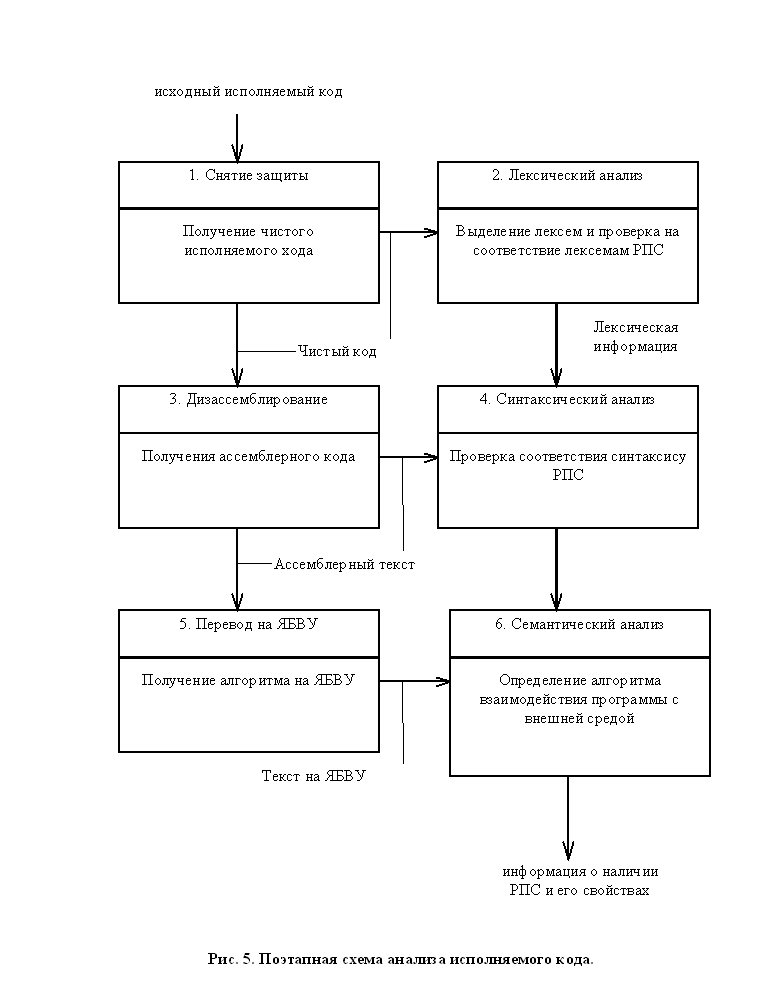
Рис. 5. Поэтапная схема анализа исполняемого кода
Задачей первого этапа анализа исполняемого кода программ является подготовка его к этапу лексического анализа и дизассемблирования. Можно назвать две основные причины, по которым исполняемый код может быть затруднен для дизассемблирования. Это:
Таким образом, преобразованный код будет состоять из процедуры защиты (дешифровки) и защищенной (зашифрованной) части, а алгоритмам, отвечающим за восстановление чистого кода, необходимо проделать обратные действия:
Здесь мы сталкиваемся с той же проблемой: чтобы удалить систему защиты, надо понять, как она работает, т.е. провести семантический анализ ее алгоритма.
Однако, если ввести ограничение (справедливое для большинства защит и упаковщиков программ), что система защиты не включается в программу на этапе ее разработки, а внедряется в уже готовый исполняемый файл (также, как и вирусы), то анализа системы защиты возможно избежать и автоматизировать восстановление исходного кода с помощью т.н. "универсальных распаковщиков" (блок 9.5 на рис 8). Это следует из того, что в этом случае система защиты отрабатывается сразу, при любом наборе входных данных. И после ее отработки можно снять дамп памяти, содержащий уже расшифрованный код.
Здесь возникает всего две проблемы:
Для системы MS DOS известно много "универсальных распаковщиков" (UUP, Intruder, AutoHack), позволяющих не просто получить код в виде дампа памяти, а обычный нормально запускающийся EXE-файл. Не вдаваясь в подробности, заметим, что для генерации EXE-файла необходимо еще и определить, какие данные относятся к таблице перемещения и восстановить ее. Это достигается тем, что исходная программа запускается два раза с разных адресов и данные, корректируемые таблицей перемещения, в двух разный дампах оказываются неодинаковыми.
Если же система защиты не является такой простой, то в этом случае на помощь могут прийти трассировщики (блок 9.2 рис. 8)[6]. Они записывают каждую инструкцию, проходящую через процессор (т.е. содержимое ячейки, на которую указывает IP) в специальную область памяти или файл, совершенно "не вникая", путем каких преобразований была получена эта инструкция, запоминая таким об разом список действительно исполняемых команд, трассу (trace).Очевидность этого метода следует из того, что любая система защиты должна восстановить исходный код по крайней мере в момент считывания его центральным процессором. Однако трассировщики применимы только тогда, когда система защиты не включает и динамическую защиту. В противном случае она может распознать изменения, вносимые трассировщиком в вычислительную среду.
Получаемый трассировщиком код, конечно, не очень похож на компилированный, однако в нем можно автоматически выделить процедуры, циклы и т.п., сократив его в десятки раз. Это можно делать как сразу, по мере получения трассы, так и потом, работая уже с готовой.
Если же в результате этого этапа не удалось получить стандартный код, это уже может служить основанием для отнесения входной программы к подозрительным, т.к. она использует весьма сложную систему защиты, что подавляющему большинству полезных программ явно не нужно.
(Пока не введены определения последующих этапов, необходимо заметить, что они появятся автоматически, как только будет дано определение лексемы. Весь излагаемый материал строится на аксиоме, что лексемой является сигнатура РПС, но совершенно не лишены смысла и другие ее определения. Например, вполне возможно ввести как лексему машинную команду).
Согласно [17], лексический анализ -- это процесс распознавания транслятором во входном тексте смысловых единиц (лексем): идентификаторов, чисел, операторов и т.п. По аналогии, лексическим анализом при исследовании исходного кода программ будем называть процесс поиска и распознавания лексем, которыми в данном случае будут являться определенные регулярные последовательности, называемыми сигнатурами РПС (блок 8.1 рис. 8).
Определение сигнатуры РПС отличается от определения сигнатуры вируса и звучит как: "Сигнатурой РПС называется любая регулярная последовательность байт, встречающаяся в исполняемом коде РПС". Таким образом, сигнатуры вирусов -- это частный случай сигнатур РПС.
Функцией лексического анализатора, несколько выпадающей из общей схемы анализа, является т.н. "экспресс-анализ" (блок 2.1 рис. 8) -- поиск сигнатур известных РПС, нахождение которых однозначно свидетельствует, что программа содержит "вредный" код (т.е. той или иной РПС), и в этом случае не требуется дальнейшего исследования.
До сих пор именно лексический анализ являлся основным и очень эффективным средством поиска вирусов (см. п. 1.1.1). Это связано с весьма большим быстродействием и простотой в реализации, позволяющей также исправлять и наращивать базу искомых сигнатур. Именно эти характеристики позволяют применять лексический анализ в качестве начального этапа анализа исполняемого кода -- "экспресс-анализа".
Рассмотрим подробнее, какого вида регулярные последовательности можно применять для этом этапе для наиболее полного и эффективного поиска разных классов РПС.
Самым простым их видом являются последовательности байт определенной длины или т.н. простые байтовые сигнатуры. Они могут записываться в десятичном, шестнадцатиричном, двоичном или символьном виде, а алгоритмы их поиска эффективны и широко описаны [18].
Однако не все вирусы и другие РПС имеют такие сигнатуры. В частности, многие вирусы часто вставляют в свой код некоторое переменное число байтов, чтобы довести размер зараженной программы до числа, кратного 16 (округление по границе параграфа). Далее, в теле вируса могут быть неизвестные заранее последовательности байт определенной длины, попадающие в него из заражаемой программы (например, первые байты из начала заражаемой программы).
Наличие таких фрагментов в разных местах тела вируса, с одной стороны, резко уменьшает длину максимальной байтовой сигнатуры и, с другой, увеличивает число таких сигнатур, каждую из которых можно использовать для поиска вируса. Конечно, для осуществления поиска любых вирусов, имеющих сигнатуру, в принципе можно было бы использовать и такие короткие простые байтовые сигнатуры, но для увеличения длины сигнатуры и, соответственно, существенного повышения качества диагностирования, вводятся так называемые регулярные сигнатуры.
Эти более сложные сигнатуры можно искать, применяя широко известные регулярные выражения, отсюда их название. Эти сигнатуры являются расширениями простых байтовых сигнатур с помощью двух специальных символов: '*' и '?'. Первый означает любое количество (0 и больше) байт, а второй строго один байт. Таким образом, сигнатура
EB ? ? FF * FF
может означать
EB 10 00 FF FF EB FF FF FF FF FF и т.д.
К сожалению, мысль создателей РПС с точки зрения их маскировки пошла дальше. Сначала появились вирусы, самошифрующиеся с переменным ключом. Очевидно, что для такого вируса в качестве сигнатуры может выступать только фрагмент незашифрованного кода, т.е. расшифровщик, который обычно представляет собой очень короткую последовательность байт, что ухудшает качество их диагностирования. Но потом появились вирусы, вообще не содержащие ни простых, ни регулярных байтовых сигнатур -- так называемые вирусы с самомодифицирующимся расшифровщиком. Это вирусы, использующие помимо шифрования кода, специальную процедуру расшифровки, изменяющую саму себя в каждом новом экземпляре вируса. Достигается это за счет того, что один и тот же алгоритм можно реализовать большим количеством способов на конкретном языке. Например, в машинных кодах (т.е. в исполняемом коде) можно:
Для поиска таких вирусов пришлось применить новый тип сигнатур: битовые регулярные сигнатуры. Первый способ изменения кода легко обходится использованием уже известного символа '*', который имеет здесь тот же смысл, что и выше: 0 или более байт. (Отметим, что именно байт, а не бит, т.к. вряд ли существует машинный язык, на котором команды имели бы переменное число бит). Второй способ -- чередование используемых регистров -- описывается введением битового символа '?', означающего битовый 0 или 1. Дело в том, что регистр, используемый в команде, кодируется либо в каком-то конкретном байте этой команды (и тогда можно применять более эффективный символ '*'), либо в конкретных битах команды, а остальные биты остаются постоянными. (Для MS DOS справедлив второй случай). Третий способ -- чередование команд местами -- может быть обойден введением асинхронных выражений, выделяемых символами начала '{' и конца '}'. Все группы байт, попадающих в эти выражения, могут быть переставлены местами во входной последовательности. Регулярная битовая сигнатура и ей соответствующая последовательность представлены на рис. 6:

Рис. 6. Пример регулярной битовой сигнатуры
Однако в 1992 г. появились вирусы, для поиска которых непригодны даже регулярные битовые сигнатуры! Это все те же вирусы с самомодифицирующимся расшифровщиком, но использующие очень совершенный алгоритм такой самомодификации, называемый MtE (Mutant Engine). В нем, помимо приведенных выше способов мутации, применяется еще и четвертый:
Расшифровщик, сгенерированный по этому алгоритму, не имеет ни одного постоянного бита, а используется в нем более половины всех инструкций процессора 8086. Таким образом, лексический поиск для таких вирусов просто неприменим (см. п. 1.1.1).
Вместо регулярных битовых сигнатур гораздо более удобно использовать регулярные ассемблерные сигнатуры, являющиеся их расширением. Они избавляют пользователя от необходимости перевода вручную самомодифицирующегося кода в регулярные битовые последовательности. Их элементами являются ассемблерные команды и расширенные регулярными выражениями, состоящие из префикса и регулярного символа. В качестве префикса могут выступать: x, l, h -- означают регистр, его младший и старший байт соответственно;
s -- сегментный регистр; c -- команду; o -- операнд; a -- адрес; без префикса -- всю команду.
К регулярным символам добавились, помимо '*' и '?', цифры, означающие конкретный объект. Например, x1 означает любой (но один и тот же в данном регулярном выражении) регистр.
Символ '*' применяется только к целой команде и не имеет префиксов.
Приведем примеры таких сигнатур:
mov x1, ax cmp x1, 4B00h je 070
Эта конструкция означает присваивание в любой регистр регистра AX, а затем сравнение именно этого регистра с числом 4B00h и переход по конкретному относительному адресу.
c? o?, 15FEh
Это -- любая двухоперандная инструкция с числом 15FEh.
{
mov x1, a?
mov x2, 100h
}
a1:
xor byte ptr cs:[x1], o?
{
inc x1
*
dec x2
}
*
cmp x2, 0
jne a1
Пример очень простого самомодифицирующегося расшифровщика.
Регулярные ассемблерные сигнатуры реализованы переводом их в регулярные битовые последовательности, расширенные символами i, j,... r для конкретных регулярных символов 0..9. Первый пример переводится в следующую последовательность:
10001011 11jjj000 00111001 11jjj000 01001011 00000000 01110100 01110000
Дальнейшим расширением регулярных сигнатур могли бы служить так называемые макрокоманды. Например, макрокоманда
MOV ah, 25h (записывается большими буквами)
означает любую последовательность команд, приводящую в конечном счете к присваиванию в регистр AH числа 25h, причем манипуляции с другими регистрами, памятью и т.п. здесь нас не интересуют. Ясно, что подходящих регулярных последовательностей команд может быть бесконечно много, например:
*
xchg ah, h1
*
add ah, 5h
pop ax
Однако здесь, также как и при реализации транслятора, необходимо найти разумный компромисс между лексическим и синтаксическим анализом и не перекладывать задачи первого на второй и наоборот. Поэтому поиск макрокоманд вряд ли необходим в лексическом анализаторе. (По крайней мере, без средств динамического исследования он не может быть реализован).
Дизассемблированием называется процесс перевода программы из исполняемых или объектных кодов на язык ассемблера.
Задача дизассемблирования практически решена и не будет поэтому здесь рассматриваться. Для MS DOS существует много хороших дизассемблеров, почти стопроцентно справляющихся со стандартным кодом. (Дизассемблированный текст может считаться 100% правильным, если при повторном ассемблировании получается исходный код. Аналогично, код считается 100% стандартным, если дизассемблер получает 100% правильный текст).
С помощью этапа дизассемблирования поэтому можно проверить качество выполнения этапа получения чистого кода если дизассемблер не генерирует 100% правильный код, то тот этап был не закончен.
В системе анализа исполняемого кода программ однако удобнее применять не стандартные дизассемблеры, а специализированный (блок 8.2 рис. 8), который, помимо ассемблерного текста, может выдавать и другую полезную информацию. Самой важной для следующего этапа будет информация о передаче управления в программе, т.е. последовательность вызова процедур.
Синтаксическим анализом при проектировании компиляторов называют процесс отождествления лексем, найденных во входной цепочке, одной из языковых конструкций, задаваемых грамматикой языка. Иначе его можно рассматривать как процесс построения дерева грамматического разбора. По аналогии будем говорить, что синтаксический анализ исполняемого кода программ состоит в отождествлении сигнатур, найденных на этапе лексического анализа, одному из видов РПС.
Для синтаксического анализа любого языка необходимо иметь его грамматику, описывающую, по каким правилам из лексем (терминальных символов или терминалов) строятся его предложения. Т.е., применительно к РПС, мы должны формализовать "грамматику" РПС, описывающую, по каким правилам из лексем (сигнатур РПС) строятся "предложения" (т.е. различные типы РПС). Это можно сделать с помощью любой формы записи грамматики, например БНФ. Но т.к. грамматика является очень простой и не содержит, в частности, рекурсии, то нагляднее всего отобразить ее в виде дерева, которое будем назвать грамматическим деревом или деревом свертки (рис. 7):
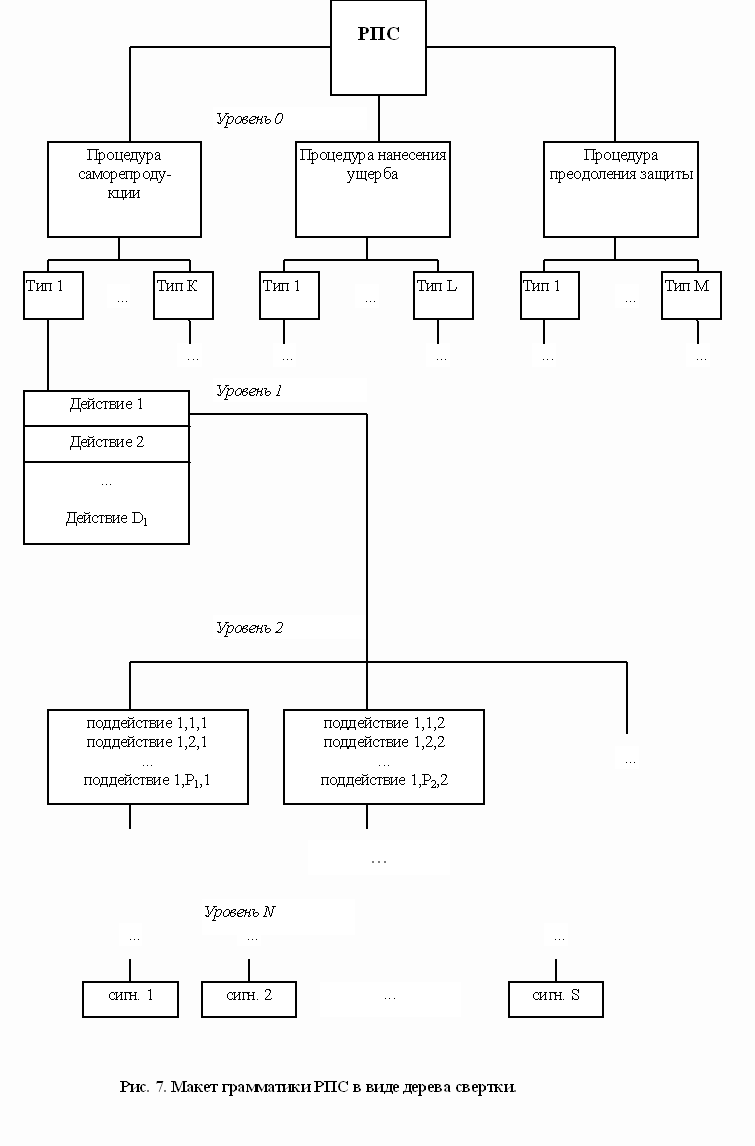
Рис. 7. Макет грамматики РПС в виде дерева свертки
Уровень 0 представляет собой конкретные типы РПС, на уровне 1 они раскрываются достаточно общими функциями, описывающими их алгоритм, на уровне 2 каждая из этих функций конкретизируется функциями более низкого уровня и т.д. до уровня N, где появляются сигнатуры. Таким образом, уровни 0..N-1 содержат нетерминалы, а уровень N -- терминальные символы.
Если бы существовала полная аналогия между анализом программ в исполняемом коде и компиляцией, то на этом этапе анализ программ мог быть закончен, т.к. входная цепочка лексем (исполняемый код) должна была бы быть либо принята синтаксическим анализатором (РПС присутствует), либо отвергнута (РПС нет). Однако при компиляции программ цепочка задается абсолютно строго: известны ее длина, порядок следования терминальных символов и т.п. Так же строго задается и грамматика входного языка.
При анализе исполняемого кода это не так:
Таким образом, окончательное заключение об отсутствии или наличии РПС можно дать только на этапе семантического анализа, а задачу этого этапа можно конкретизировать как свертку терминальных символов в нетерминалы как можно более высокого уровня там, где входная цепочка задана строго.
Этот этап выполняется с полученным ассемблерным текстом программы и состоит в нахождении и выделении соответствующим образом управляющих конструкций, таких как: циклы, подпрограммы и т.п.; основных структур данных. В какой-то мере этот этап также уже реализован: в частности, дизассемблер Sourcer ((с) V Communications) выделяет процедуры и некоторые структуры данных еще на этапе дизассемблирования, а для выделения управляющих конструкций служит специальная утилита ASMTool (блок 8.4 рис. 8).
Семантический анализ программы, как уже отмечалось, удобнее всего вести на языке высокого уровня. Однако на сегодняшний день задача о переводе из машинных кодов на язык высокого уровня (дискомпиляции -- блок 8.3 рис. 8) не имеет приемлемого решения. Поэтому на данном этапе вполне подходящим языком более высокого уровня мог бы стать специализированный макроассемблер, который был описан в п. 3.1.1. Специализированным он называется в том плане, что нацелен на выделение макроконструкций, используемых в РПС. Не нужно смешивать этот процесс с возможным переводом на язык макроассемблера на предыдущих этапах, т.к. там осуществлялась свертка лексем, а не перевод всего текста.
Семантический анализ программы -- исследование программы изучением смысла составляющих ее функций (процедур) в аспекте операционной среды компьютера [19].
Введенное определение существенно отличается от толкования понятия "семантический анализ программ" из [17], поскольку там оно интерпретируется только с позиции транслятора программы с языка высокого уровня. Но перевод программ с языка высокого уровня в исполняемые коды не лишает ее смысла, поэтому такое определение не может претендовать на полноту. Напротив, новое определение подразумевает полное сохранение смысла программы и ее интерпретацию компьютерной системой при любой форме представления. Этот этап должен дать окончательный ответ на вопрос о том, содержит ли входной исполняемый код РПС, и если да, то какого типа. При этом он использует всю полученную на предыдущих этапах информацию, которая, как уже отмечалось, может считаться правильной только с некоторой вероятностью, причем не исключены вообще ложные факты или умозаключения.
Таким образом, формально на этапе семантического должна быть закончена свертка нетерминалов, полученных на этапе синтаксического анализа, в нетерминалы уровней 0, 1, 2. Очевидно, что нечеткость имеющейся информации приводит к появлению на этом этапе некоторой машины логического вывода (блок 10 рис. 8) со всеми присущими ей элементами: форме представления знаний и правил, алгоритмами логического вывода, вероятностными заключениями и т.п.
В целом, задача семантического исследования исполняемого кода программ является очень сложной и нуждается в серьезных исследованиях. Вероятнее всего, что полностью автоматизировать ее будет невозможно.
Как мы видим, оба этапа -- синтаксического и семантического анализа -- преследуют общую цель: построить дерево грамматического разбора и тем самым закончить анализ кода.
Известно, что при построении компиляторов все методы синтаксического анализа можно разбить на два класса: восходящие и нисходящие. Первые (методы сверху вниз) начинают с правила грамматики, определяющего конечную цель анализа, и пытаются так наращивать дерево грамматического разбора, чтобы его узлы соответствовали синтаксису анализируемой цепочки. Вторые (методы снизу вверх) берут за основу терминальные символы и пытаются их свернуть в нетерминалы все более и более высоких уровней.
Совершенно аналогично, в теории экспертных систем различают два подхода: с прямой цепочкой рассуждений и с обратной. Первые, опираясь на известные факты, пытаются по ним построить умозаключение. Вторые, наоборот, беря за основу некоторую гипотезу, пытаются найти данные для ее подтверждения или опровержения.
Похоже, применительно к нашей задаче, эти пары методов являются разными точками зрения на одно и тоже, и, говоря о взаимодействии методов синтаксического и семантического анализа, мы приходим к двум основным объединенным методам анализа исполняемого кода: нисходящие с прямой цепочкой рассуждений и восходящие с обратной цепочкой рассуждений.
Первые последовательно строят гипотезы, что РПС относится к типу 1, типу 2 и т.д. (т.е. начинает с корня дерева свертки) и постепенно спускаются вниз, на каждом этапе пытаясь опровергнуть или подтвердить свою гипотезу, ища соответствующие сигнатуры. Вторые начинают с терминалов уровня N и постепенно поднимаются вверх, сворачивая их в нетерминалы высших уровней с соответствующими вероятностями.
Можно охарактеризовать эти методы и с другой точки зрения: первые можно назвать методами ведущего семантического разбора (где машина логического вывода является первичной, а синтаксический анализатор помогает ей в подборе фактов), а вторые методами ведущего синтаксического разбора (где первичной будет синтаксическая свертка, которую облегчают вероятностные рассуждения семантического анализатора). К точно таким же выводам приходят авторы в [19], рассуждая с несколько других позиций. Более того, они предлагают как наиболее эффективный и многообещающий метод, основанный на сочетании этих двух, но ведь именно сочетание методов логического вывода привело к созданию машины логического вывода с косвенной цепочкой рассуждений [20], которая объединяет достоинства как первого, так и второго подхода.
Общая структура отражает взаимодействие основных модулей системы анализа, описанных выше, а также управляющих модулей, методов статического и динамического исследования и интерфейса с пользователем (рис. 8). Она несколько отличается от приведенной в [19].
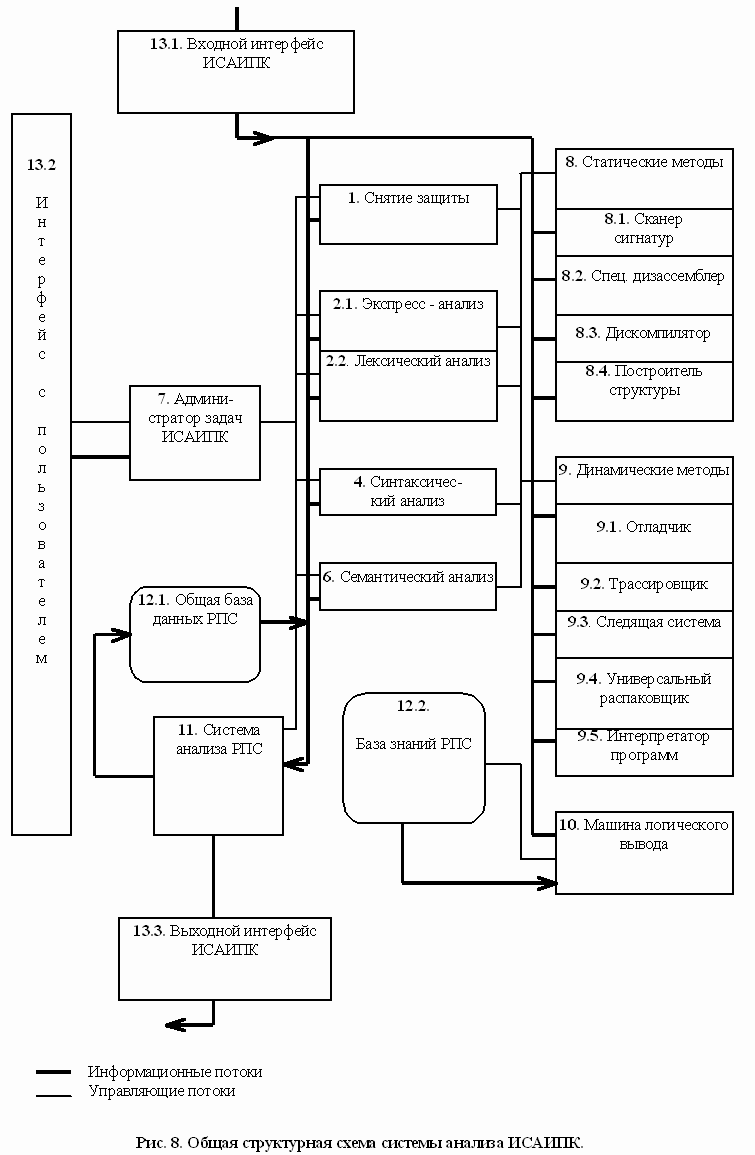
Рис. 8. Общая структурная схема системы аналища ИСАИПК
Объект исследования -- исполняемый код программы -- поступает на входной интерфейс ИСАИПК (13.1) для согласования фактической формы представления входной информации с требуемой формой ее представления для ИСАИПК.
Администратор задач ИСАИПК (7) посредством интерфейса с пользователем (13.2) начинает диалог с пользователем по конкретизации цели исследования. Полученная от него информация дает возможность администратору сделать выбор по передаче управления между подсистемами ИСАИПК. В дальнейшем администратор принимает решения о дальнейших передачах управления, продолжении или прекращении исследования и т.д.
Основные этапы анализа (1, 2, 4, 6) описаны выше. Для своих целей они применяют статические (8) или динамические (9) методы исследования, а семантический анализатор еще и машину логического вывода (10).
По завершению процесса анализа администратор передает управление системе анализа РПС, которая определяет его свойства и заносит в общую базу данных (12.1). Результаты анализа поступают на выходной интерфейс (13.3).
Доведение предложенных в этой главе общих схем системы анализа до программной реализации ИСАИПК на сегодняшний день представляется весьма проблематичным из-за сложности и неоднозначности применяемых в них алгоритмов.
Поэтому в следующей главе мы рассмотрим практическую реализацию некоторой подсистемы ИСАИПК (блоки 2.2, 4, 6, 8.1, 8.2, 10, помеченные '*'), выполняющую, однако, ее основную функцию поиск неизвестных РПС в исполняемом коде программ для операционной системы MS DOS.
Для доказательства практического применения идей, рассмотренных в предыдущей главе, необходимо было построить макет ИСАИПК, получивший название SubLVA. С самого начала, при разработке технического задания на эту программу, было введено ограничение, что она не будет использовать методы динамического анализа исполняемого кода. Это, конечно, уменьшает мощность программы, но, с другой стороны, значительно увеличиваются скорость, надежность и простота проектирования. Не использование средств динамического исследования также приводит к тому, что первый этап -- снятие защиты -- не присутствует в системе SubLVA, которая получает на вход уже "чистый" код. Этот этап, тем не менее, можно реализовать как внешний, не нарушая логики приведенных схем анализа.
Первоочередной задачей для реализации ИСАИПК является построение максимально полного дерева свертки, общая структура которого была представлена в предыдущей главе на рис. 7. Для реализации системы анализа необходимо наполнить это дерево конкретными узлами, присущими РПС. Для системы SubLVA оказалось достаточно ограничить глубину этого дерева 5 уровнями (т.е. N=4).
Ниже приведено используемое в системе дерево свертки (с сокращениями), представленное описанием в форме Бэкуса-Науэра (БНФ).
ПСР ::= ПСР.Одиночная | ПСР.Сетевая ПСР.Одиночная ::= ПСР.Резидентная | ПСР.Файловая | ПСР.Бутовая ПСР.Сетевая ::= Не_Рассматр ПНУ ::= ПНУ.Файл | ПНУ.Видео | ПНУ.Порт | ПНУ.Клавиатура | ПНУ.Система ПНУ.Файл ::= ПНУ.Формат | ПНУ.BOOT_MBR_FAT | ПНУ.Сектор | ПНУ.Исполн_Файл ПНУ.Видео ::= Не_Рассматр ПНУ.Клавиатура ::= ПНУ.Блокировка_Клав | ПНУ.Запись_Клав ПНУ.Система ::= ПНУ.Зависание | ПНУ.Перезагрузка | ПНУ.Замедление | ПНУ.Блокировка_Запуска ППЗ ::= ППЗ.Системная | ППЗ.Дополнительная ППЗ.Системная ::= Пусто ППЗ.Дополнительная ::= ППЗ.Вход | ППЗ.Программа | ППЗ.Антивирус
ПСР.Резидентная ::=
Проверить_Наличие.Память
Выделить.Память
Перехватить.Прер
Скопироваться.Память
Замести_Следы.Память
ПСР.Файловая ::=
Найти_Жертву.Файл
Проверить_Тип.Файл
Проверить_Наличие.Файл
Скопироваться.Файл
Замести_Следы.Файл
ПСР.Бутовая ::=
Проверить_Наличие.BOOT
Найти_Место.BOOT
Скопироваться.BOOT
Замести_Следы.BOOT
ПНУ.Формат ::= Отформатировать_Дорожку
ПНУ.BOOT_MBR_FAT ::= Записать.BOOT | Записать.MBR | Записать.FAT
ПНУ.Сектор ::= Записать.Абс
ПНУ.Исполн_Файл ::= Записать.Исполн_Файл
ПНУ.Блокировка_Клав ::= Не_Рассматр
ПНУ.Запись_Клав ::= Записать_Буфер.Клав
ПНУ.Зависание ::= Бесконеч_Цикл
ПНУ.Перезагрузка ::= Вызвать_Перезагр
ПНУ.Замедление ::= Замедлить.Таймер
ПНУ.Блокировка_Запуска ::=
Проверить.EXEC
Сравнить.EXEC
Проверить_Наличие.Память ::= Вызвать.Нестд_прер | Вызвать.Нестд_функц |
Сканировать.Память
Выделить.Память ::= int21.AA | Манипуляция.MCB | Системная_Область
Скопироваться.Память ::=
Найти_себя.Память
Скопировать.Память |
Остаться_Резидентным
Перехватить.Прерывание ::= int21.25 | Запись_Табл
Замести_Следы.Память ::= Пусто
Найти_Жертву.Файл ::= Поиск.PATH | Поиск.Тек_каталог | Поиск.Корень |
Поиск.Дерево | Поиск.Все_диски | Поиск.COMMAND
Поиск.PATH ::=
Считать.PATH
Сканировать.PATH
Проверить.Файл
Поиск.Тек_каталог ::= Проверить.Файл
Поиск.Корень ::=
ChDir.Root
Проверить.Файл
Поиск.Дерево ::=
FindFirst
Проверить.Дир
Считать.DTA
Поиск.Дерево
Записать.DTA
FindNext
Поиск.Все_диски ::=
Найти_колич.Диск
Перейти.Диск
Поиск.Дерево
Поиск.COMMAND ::= Считать.COMSPEC | C.COMMAND.COM
Проверить_Тип.Файл ::=
Считать_Начало.Файл
Проверить.MZ
Проверить_Наличие.Файл ::= Проверить.Дату_Время | Проверить.Сигнатуру
Скопироваться.Файл ::= Скопироваться.COM | Скопироваться.EXE |
Скопироваться.BAT | Скопироваться.SYS
Скопироваться.COM ::=
Проверить.Условие_Заражения.COM
Снять.Read_Only.Файл
Запомнить.Дату.Файл
Открыть_Запись.Файл
Считать_Начало.Файл
Записать_Конец.Файл
Записать_Начало.Файл
Закрыть.Файл
Поставить.Дату.Файл
Поставить.Read_Only.Файл
Скопироваться.EXE ::=
Проверить.Условие_Заражения.EXE
Снять.Read_Only.Файл
Запомнить.Дату.Файл
Открыть_Запись.Файл
Считать_Заголовок.Файл
Записать_Конец.Файл
Записать_Заголовок.Файл
Закрыть.Файл
Поставить.Дату.Файл
Поставить.Read_Only.Файл
Замести_Следы.Файл ::= Не_рассматр
Проверить_Наличие.BOOT ::=
Считать.BOOT
Проверить.Сигнатуру |
Считать.Метку_Диска
Проверить_Сигнатуру
Найти_Место.BOOT ::= Свободный_Сектор | Системный_Сектор |
Новый_Сектор
Новый_Сектор ::= Форматировать_Дорожку
Скопироваться.BOOT ::=
Считать.BOOT
Записать.Сектор
Записать.BOOT
Замести_Следы.BOOT ::= Пометить_Сбойный.Сектор
Пометить_Сбойный.Сектор ::=
Поиск_FAT.Сектор
Пометить_BAD.FAT
Замедлить.Таймер ::=
Считать.Прер.Таймер
Обработчик_Цикл
Записать.Прер.Таймер
ППЗ.Вход ::= Пусто
ППЗ.Программа ::= ППЗ.Программа.ADM | ППЗ.Программа.Stacker |
ППЗ.Программа.Перебор
ППЗ.Программа.ADM ::= Вскрыть.ADM
ППЗ.Программа.Stacker ::= Вскрыть.Stacker
ППЗ.Программа.Перебор ::=
Сформировать.Пароль
Вызов.Программы
ППЗ.Антивирус ::= ППЗ.Aidstest | ППЗ.Scan | ППЗ.Adinf | ППЗ.Сторож |
ППЗ.Детектор
ППЗ.Aidstest ::= Не_зараж.Aidstest
ППЗ.Scan ::= Не_зараж.Scan
ППЗ.Adinf ::= Не_зараж.Adinf | Испортить_файлы.Adinf
ППЗ.Сторож ::= Найти_обработчик.21 | Найти_обработчик.13
ППЗ.Детектор ::= Корректировать_длину.Файл | Корректировать.BOOT
Вызвать.Нестд_прер ::=
INT [00-09 34-55 87-C0] (1)
Вызвать.Нестд_функц ::=
MOV ah, [6D-FF]
int 21
Сканировать.Память ::=
MOV si, o?
MOV di, o?
MOV cx, o?
rep scas
int21.AA ::=
MOV ah, AA
int 21
Манипуляция.MCB ::= Не_рассматр
Системная_Область ::=
MOV x1, [0000 A000]
MOV s?, x1
Найти_себя.Память ::=
call 0000 (2)
pop x?
Скопировать.Память ::=
MOV si, o?
MOV di, o?
MOV cx, o?
rep movs
int21.25 ::=
MOV ah, 25
int 21
Запись_Табл ::=
MOV s1, 0 (3)
MOV s1:[a1], o?
MOV s1:[a1+2], o?
Остаться_Резидентным ::=
MOV ah, 31
MOV al, o?
MOV dx, o?
int 21 |
MOV dx, o?
int 27
Считать.PATH ::= Не_рассматр
Сканировать.PATH ::= Не_рассматр
Проверить.Файл ::=
MOV ax, 22 (4)
MOV dx, a1
int 21h
a2: *
MOV ax, 23
int 21h
*
JNE a2
a1: db '*.COM' |
db '*.EXE' |
db '*.*'
ChDir.Root ::=
MOV dx, a1
MOV ah, 3b
int 21
a1: db '\'
Считать.DTA ::=
MOV ah, 2f
int 21
c? o?, es:[bx]
Записать.DTA ::=
MOV ah, 1a
int 21
C.COMMAND.COM :: =
db 'COMMAND' | (5)
db 'COMMAND.COM' |
db 'C:\COMMAND.COM'
Считать_Начало.Файл ::=
MOV dx, o?
MOV ah, 3f
int 21
Проверить.MZ ::=
CMP x?, 'MZ' | (6)
CMP x?, 'ZM'
Проверить.Дату_Время ::=
MOV AX, 5700
int 21
Проверить.Сигнатуру ::= Не_рассматр
Проверить.Условие_Заражения.COM ::= (7)
MOV cx, 0
MOV dx, 0
MOV ax, 4202
int 21
ADD ax, o?
CMP ax, FFFF
Снять.Read_Only.Файл ::=
MOV ax, 4300 (8)
MOV dx, o?
int 21
AND cx, FFFE
MOV ah, 01
int 21
Запомнить.Дату.Файл ::=
MOV ax, 5700 (9)
int 21
[ c? o?, cx ]
c? o?, dx
Открыть_Запись.Файл ::=
MOV ah, 3d
MOV al, 2
int 21
Считать_Начало.Файл ::=
MOV ah, 3fh
MOV cx, o?
MOV dx, o?
int 21
Записать_Конец.Файл ::=
MOV cx, 0
MOV dx, 0
MOV ax, 4202
int 21
MOV ah, 40h
MOV cx, o?
int 21
Записать_Начало.Файл ::=
[ MOV cx, 0
MOV dx, 0
MOV ax, 4200
int 21
]
MOV ah, 40h
MOV cx, o?
int 21
Закрыть.Файл ::=
MOV ah, 3eh
int 21
Поставить.Дату.Файл ::=
MOV dx, o?
MOV ax, 5701
int 21
Поставить.Read_Only.Файл ::=
MOV ax, 4301
int 21
Считать.BOOT ::=
MOV ax, 0201 (10)
MOV cx, 0
MOV bx, o?
MOV dx, o?
int 13
Записать.BOOT ::=
MOV ax, 0301 (11)
MOV cx, 0
int 13
Записать.Сектор ::=
MOV ah, 03 (12)
int 13
Проверить.Сигнатуру ::= Не_рассматр
Считать.Метку_Диска ::=
MOV ah, 4e
MOV dx, o?
MOV cx, 8
int 21
Найти_обработчик.21 ::= Не_рассматр
Найти_обработчик.13 ::=
MOV dx, o? (13)
MOV ah, 13
int 2f
c? o?, ds
c? o?, dx
int 2f
int21.AA ::=
mov ah, AA
int 21
int21.AA ::=
mov ax, AA??
int 21
Таким образом, все конструкции уровня 4 представляют собой сигнатуры РПС в виде регулярных ассемблерных выражений и могут использоваться как признаки РПС, т.к. каждая содержится в том или ином РПС. Однако многие из них вполне невинны и могут содержаться в любой программе (например, как int 21.25, Открыть_Запись.Файл и т.п.). Другие же, наоборот, весьма характерны для РПС: Найти_Себя.Память, Проверить.MZ (они помечены номерами 1..13). Многие не представленные на 4 уровне выражения также будут являться характерными для РПС признаками: Пометить_BAD.FAT, Обработчик_Цикл, Не_зараж.Aidstest, Не_зараж.Scan, Не_зараж.Adinf, Испортить_файлы.Adinf, Найти_обработчик.21, Корректировать_длину.Файл, Корректировать.BOOT и т.д.
Как уже отмечалось в п. 3.2, в ИСАИПК различают два основных метода анализа: восходящий с прямой цепочкой рассуждений и нисходящий с обратной цепочкой рассуждений. Рассмотрим возможные реализации каждого из них с учетом ограничения на неиспользование динамических методов исследования.
Это восходящий метод с прямой цепочкой рассуждений.
Основная его идея состоит во том, что после построения дерева свертки из уровня N берутся наиболее типичные для РПС фрагменты (для нашего дерева это будут помеченные номерами выражения). (Вообще говоря, дерево можно не строить, а получить такие фрагменты, анализируя исходные тексты РПС и представляя основные алгоритмы их работы) и они ищутся на этапе лексического анализа. Этап синтаксического анализа практически отсутствует, а на этапе анализа семантики применяются правила, позволяющие сделать вероятностный вывод о наличии и типе РПС в исходном коде.
Для полученных нами характерных признаков это могут быть правила типа:
ЕСЛИ Проверить. Файл ТО ПСР. Файловая с вер. 40%. ЕСЛИ Проверить. Файл ТО ПСР. Резидентная с вер. 20%. ЕСЛИ Найти_Себя. Память ТО ПСР. Резидентная с вер. 80%. ЕСЛИ Записать. BOOT ТО ПСР. Бутовая с вер. 70%.
Этот метод привлекает своей простой и очевидностью алгоритмов, и первые "универсальные" антивирусы применяли именно его (первая такая программа, Lie Detector, была представлена в 1989 г.). Более того, простота в данном случае не ухудшает их эффективности в поиске неизвестных вирусов, -- Lie Detector занял первое место на Всесоюзной киевской конференции по вирусам 1990 г., детектируя 97% от известных тогда вирусов. Эта программа использовала даже более простые правила, которые сводились по сути только к присваиванию различных весов различным признакам вирусов и потом их суммированию. Если сумма превышала некоторый лимит, то программа объявлялась подозрительной.
Как характерные для вирусов признаки Lie Detector использовал следующие: "базирование", т.е. определение текущего IP (Найти_себя.Память), открытие файла на запись или смещения указателя записи в конец (Открыть_Запись.Файл и Записать_Конец.Файл), изменение даты или атрибутов у файла (Поставить.Дату.Файл, Поставить.Read_Only.Файл), строки типа "*.COM", "*.EXE", "*."', "MZ", "ZM" (Проверить_Файл, Проверить.MZ). Как мы видим, все эти признаки присутствуют и в нашем дереве на уровне 4, что подтверждает практическую его ценность.
Если к программе такого рода добавить первый этап (снятие защиты), то она может быть вполне конкурентоспособной и сегодня, а по скорости проверки с ней не сможет сравниться ни один метод. (По таблице 3 оценка такой программы равнялась бы 5.0 баллам, уступая только ревизорам!)
Недостатки у такого подхода тоже очевидны. Это все те же ошибки первого и второго рода (см. п. 1.1): программа будет подвержена многим ошибкам второго рода, срабатывая на ни в чем неповинные программы; и, реже, первого рода, если вирус применит некоторые алгоритмы, не попадающие в характерные.
Второй метод будет относиться к нисходящим с обратной цепочкой рассуждений.
Итак, строится полное дерево свертки и процесс синтаксического разбора идет сверху (иначе говоря, предполагается, что в программе присутствует РПС и последовательно строятся гипотезы, что он относится к типу 1, 2 и т.д.). Одновременно весь входной код полностью дизассемблируется (на этапе 3 рис. 5 и 8 предыдущей главы) и переводится, насколько это возможно статическими методами, на макроассемблер. Теперь для подтверждения текущей гипотезы последовательно ищутся сигнатуры, которые ее подтверждают, уже на языке макроассемблера (для нашего дерева -- это уровень 3), а дизассемблированный текст дает некоторую информацию о передачах управления в программе, т.е. о порядке следования этих сигнатур. Таким образом, эта методика включает 2, 3, 4, 5 и 6 этапы.
По достоинствам и недостаткам этом метод полностью противоположен первому, т.к. он будет весьма надежно оценивать наличие РПС в программе (если дерево свертки полно), но применяемые алгоритмы будут нетривиальны и медленны. По таблице 3 оценка такой системы равнялась бы 5.3 баллам.
Как часто встречается в практических системах, методы, применяемые в них, являются сочетанием двух, казалось бы, противоположных. Это имеет место и для рассматриваемой системы, т.к. она сочетает два вышеописанных подхода.
Для работы системы SubLVA необходимо полное дерево свертки (как и в подходе 2). В исполняемом коде на этапе лексического анализа ищутся наиболее важные или характерные для РПС сигнатуры, задаваемые регулярными ассемблерными выражениями уровня 4 (как в подходе 1). Но далее они поступают не в машину логического вывода, а на следующие этапы. На этапе 3 происходит дизассемблирование кода, расположенного непосредственно вблизи от найденной сигнатуры (выбирается некоторое фиксированное смещение). Этап синтаксического анализа заключается в переводе этого небольшого фрагмента ассемблерного текста на макроассемблер (как в подходе 2). Если перевод будет успешным, т.е. найденная ассемблерная сигнатура является действительно сворачивается в соответствующий не терминал уровня 3, то именно эти нетерминалы поступают на этап семантического анализа, правила которого практически аналогичны правилам из подхода 1.
Таким образом, данный подход сочетает в себе достоинства описанных выше:
Применяемые на этапе лексического анализа алгоритмы поиска регулярных выражений хотя и являются достаточно сложными, но широко описаны. Для поиска регулярных ассемблерных выражений, как отмечалось в п. 3.1.2, их необходимо перевести в соответствующие регулярные битовые. Для этого необходим алгоритм ассемблирования, реализация которого также не вызывает трудностей.
Применяемое на этапе 3 дизассемблирование в том виде, как оно необходимо для данной системы, будет являться однопроходным, без составления таблиц процедур и переменных и тем самым также относительно несложно. Более того, на этом этапе может вызываться внешняя процедура с параметрами -- адресами начала и конца дизассемблируемого участка (что и сделано в системе).
Этап синтаксического анализа является самым сложным для программирования. Как было подчеркнуто, выражения уровня 3 на макроассемблере могут приводить к бесконечному числу выражений уровня 4. Очевидно и обратное -- свертка сигнатур уровня 4 в сигнатуры уровня 3 может иметь бесконечное число решений. К счастью, мы знаем обе сигнатуры -- найденную и ту, в которую пытаемся свернуть. Поэтому остается только доказать, что фактически найденная сигнатура может получаться из макроассемблерного выражения.
Нет ли здесь противоречия с тем, что это вроде бы должно следовать из смысла самого дерева свертки? К сожалению, нет. Здесь и проявляются нечеткость получаемой информации. Приведем пример.
Рассмотрим макроассемблерное выражение уровня 3:
MOV ax, 0С MOV es, 00
Это выражение приводит к вполне естественному представлению на уровне 4:
mov ax, 0C mov x1, 00 mov es, x1
И в качестве конкретной сигнатуры могла бы быть найдена такая:
mov ax, 0C mov ax, 00 mov es, ax
Которая, очевидно, не является представлением искомого макровыражения.
Для решения подобной задачи обычно применяют динамические методы: ставится точка останова после последней проверяемой команды, управление передается на найденную последовательность и при останове проверяются значения регистров. Поскольку мы отказались от динамических методов, приходится в некоторой степени моделировать этот процесс.
Похожий алгоритм реализован в программе Sourcer, которая довольно точно определяет, какая и с какими параметрами была вызвана функция DOS, даже если явного присваивания в регистры сделано не было.
Для моделирования работы процессора вводится следующие структуры данных: регистры (начальное состояние каждого -- "неизвестно", небольшой стек размером 32 слова (начальное состояние -- пуст). Моделируются наиболее распространенные команды: mov, inc, dec, cmp, xchg, xor, add, sub, push, pop и некоторые другие. Приведем типичный пример ассемблерного текста, где предложенная схема правильно определит содержимое регистров (прог. 2):
push ss ; начало дизассемблируемого текста. db F6 ; Явно неправильное, т.к. попали в середину команды ... mov ax, bx ; пока ни ax, ни bx не известны mov bx, 6 push bx ; стек содержит 6 call 0123 xor ax, ax ; ax = 0 pop bx ; bx = 6, стек снова пуст mov cx, ax ; cx = 0 int F5 ; значения регистров ax, bx, cx известны ...
Прог. 2. Пример дизассемблированного текста на этапе синтаксического анализа.
Как было отмечено, блок семантического анализа представляет собой небольшую систему логического вывода, состоящую из машины логического вывода, работающую с фактами (сигнатурами) уровня 3 и базы знаний. База знаний представляет собой правила, по которым может быть проведена вероятностная свертка с уровня 3 на уровень 0. Машина логического вывода оперирует этими правилами и производит эту свертку, получая на выходе выражение уровня 0, т.е. тип РПС с некоторой вероятностью.
В машине логического вывода применен широко известный байесовский подход к вычислению вероятностей [20], который оказывается очень адекватным для данной предметной области.
Суть его состоит в следующем. Проверке подлежит некоторая гипотеза Н, с которой связаны некоторые утверждения А1, А2 и т.д. Тогда, проверив одно из них (A), мы можем пересчитать вероятность гипотезы Н с учетом истинности (форм. 4.1) или ложности (форм. 4.2) этого утверждения:
 (4.1)
(4.1)
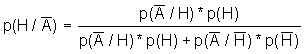 (4.2)
(4.2)
где:
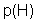 -- априорная вероятность H;
-- априорная вероятность H;
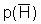 -- априорная вероятность (не Н), т.е. 1 - p(H);
-- априорная вероятность (не Н), т.е. 1 - p(H);
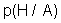 ,
,
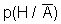 -- апостериорные вероятности гипотезы Н;
-- апостериорные вероятности гипотезы Н;
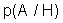 -- вероятность A, если H верна;
-- вероятность A, если H верна;
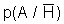 -- вероятность A, если H неверна;
-- вероятность A, если H неверна;
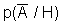 -- вероятность (не A), если H верна, т.е. 1 - p(A/H);
-- вероятность (не A), если H верна, т.е. 1 - p(A/H);
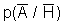 -- вероятность (не A), если H неверна, т.е. 1 -
.
-- вероятность (не A), если H неверна, т.е. 1 -
.
Для нашего исследования гипотезами будут все выражения уровня 0 (например, пусть проверяется гипотеза H, что РПС -- резидентный вирус), а утверждениями -- сигнатуры уровня 3 (например, Остаться_Резидентным). Тогда для получения p(H/A) или необходимо знать:
, т.е. вероятность того, любая другая программа может использовать эту функцию. Величина 0.02 вполне подойдет, т.к. резидентных программ не так много.Таким образом, если в коде мы находим сигнатуру Остаться_Резидентным, то по формуле 4.1 получим вероятность того, что это -- резидентный вирус, равную 0.024 (т.е. она увеличится 25 раз), а если нет, то по формуле 4.2 -- 0.00051 (т.е. уменьшится вдвое). И теперь эта вероятность может выступать в качестве априорной p(H) на следующем шаге, при проверке следующего утверждения, увеличиваясь или уменьшаясь таким образом в зависимости от истинности или ложности текущего утверждения.
В конце мы получим конечные вероятности всех гипотез р(H1/A1A2...As), p(H2/A1A2...As) ... p(Hg/A1A2...As), где g=K+L+M (рис. 7), из которых выбираются те, вероятность которых превышает некоторый порог P (для системы SubLVA P=0.7).
Для данной предметной области байесовский подход имеет следующие преимущества:
для каждой гипотезы, отражающей тот факт, что эта сигнатура может встретиться в "полезной" программе, позволяет применять формулы 4.1 и 4.2, не задумываясь о том, насколько характерной для РПС является данная сигнатура;Пусть вероятность свертки равна r, тогда из 4.1 и 4.2 получается одна общая формула
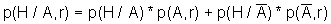 (4.3)
(4.3)
где:
p(H/A,r) -- вероятность гипотезы H с учетом истинности утверждения A с вероятностью r;
p(H/A), -- вычисляются по формулам 4.1 и 4.2;
p(A,r) -- функция учета неопределенности утверждения A;
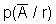 = 1 - p(A,r).
= 1 - p(A,r).
Функция p(A,r) должна удовлетворять следующим условиям:
p(A,0) = 0
p(A,1) = 1
p(A,0.5) ищется как решение уравнения
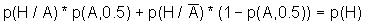 (4.4),
(4.4),
т.е. при отсутствии информации относительно A вероятность p(H/A) не изменяется и остается равной априорной p(H). Решением этого уравнения является
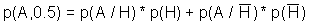 (4.5)
(4.5)
Итак, в базе знаний необходимо иметь следующую информацию: гипотезы принадлежности к тому или иному типу РПС (g штук) плюс априорную вероятность каждой из них p(H) и утверждения -- сигнатуры (s штук) плюс две вероятности p(A/H), для каждой.
База знаний имеет следующий формат:
Тип_РПС.Уровень.0 ЕСЛИ p(H) // Комментарий Сигнатура.Уровень.3 p(A/H) [Image110.gif]
а фрагмент ее приведен на рис. 9:
ПСР.Резидентная ЕСЛИ 0.001 // Уровень 1 - Проверить_Наличие.Память Вызвать.Нестд_прер 0.4 0.03 Вызвать.Нестд_функц 0.4 0.03 Сканировать.Память 0.2 0.1 // Уровень 1 - Выделить.Память int21.AA 0.3 0.9 Манипуляция.MCB 0.5 0.001 Системная_Область 0.2 0.01 // Уровень 1 - Перехватить.Прер int21.25 0.35 0.95 Запись_Табл 0.65 0.01 // Уровень 1 - Скопироваться.Память Найти_себя.Память 0.8 0.001 Скопировать.Память 0.95 0.95 Остаться_Резидентным 0.5 0.02 ПСР.Файловая ЕСЛИ 0.001 ... ППЗ.Дополнительная ЕСЛИ 0.0001 ...
Рис. 9. Фрагмент базы знаний системы SubLVA.
При анализе приведенной базы можно выявить некоторые ее любопытные особенности. Например, сигнатура int21.AA у вирусов встречается реже, чем у нормальных программ, т.к. они чаще пытаются выделить под себя память незаметно, а все нормальные программы делают это "законными" методами. Это крайний случай того, о чем говорилось в п. 4.4.2.1. А сигнатура Скопировать.Память одинаково часто встречается и в вирусах, и в полезных программах(и, наверное, является вообще одним из самых распространенных действий) и поэтому ее поиск не даст, вообще говоря, никакой новой информации относительно наличия вируса (формулы 4.1 и 4.2 вырождаются в p(H/A) = [Image108.gif] = p(H) ).
Система SubLVA показала себя вполне работоспособной, несмотря на то, что использовала далеко не полное дерево свертки и очень грубые оценки вероятностей в базе знаний. Алгоритмы, применяемые в ней, действительно являются достаточно быстрыми, например, анализ средней программы в 30 Кбайт занимает несколько секунд на машине класса 80486DX2-66. Степень достоверности выдаваемой ей информации составила порядка 80% на тестовых примерах, состоящих из реальных экземпляров РПС. Она, бесспорно, подвержена ошибкам первого и второго рода, в частности, оказалось, что почти все программ защиты классифицировались ей как РПС. (Это, вообще говоря, неудивительно, если принять во внимание постоянное их соперничество).
Система нуждается в совершенствовании, как в доработке применяемых алгоритмов (см. п. 4.4.2.1, учет неопределенности при нахождении сигнатуры), так и в присоединении остальных блоков из общей схемы ИСАИПК (в частности, введении динамического анализа).