
Diomidis Spinellis
IEEE Transactions on Information Theory, 49(1), pp. 280-284, January 2003.
ISSN 0018-9448
January 2003
 Download PDF (69.54Kb) (You need to be registered on forum)
Download PDF (69.54Kb) (You need to be registered on forum)D. Spinellis is an Assistant Professor in the Department of Management Science and Technology at the Athens University of Economics and Business, Athens, Greece. E-mail: dds@aueb.gr.
A virus is a program that replicates itself by copying its code into other files. A common virus protection mechanism involves scanning files to detect code patterns of known viruses. We prove that the problem of reliably identifying a bounded-length mutating virus is NP-complete by showing that a virus detector for a certain virus strain can be used to solve the satisfiability problem. The implication of this result is that virus identification methods will be facing increasing strain as virus mutation and hosting strategies mature, and that different protection methods should be developed and employed.1 2
One often-used defence against computer viruses is the execution of an anti-virus program that detects and cleans programs that appear to be infected. Virus writers respond to this defence by trying to thwart anti-virus software through targeted attacks, mutations, or social engineering. Mutating viruses are a particularly insidious threat, because detection algorithms need to be constantly updated and to spend increasing processing time to identify new mutation types. The question of whether complexity theory is on the side of virus writers or the protection vendors could have important practical implications. In this paper we will prove that there exist realistic viruses whose reliable detection is of NP-complete complexity [1] and that therefore the general problem of reliable bounded-length virus identification is NP-complete.
Intentionally created malicious software [2] - often termed malware - is typically classified into Trojan horses, viruses, and worms [3]. A Trojan horse is a program that exploits the rights of its user to perform an action its user does not intend, a virus is a Trojan horse that replicates itself by copying its code into other program files [4], while a worm is an independently-running program that replicates through a network exploiting security weaknesses to invade other computers.
A number of virus prevention and detection methods have been proposed and are commonly implemented [5], [6]. Reference [7] contains an annotated bibliography of malware analysis and detection papers. Prevention methods involve limiting the flow of information between programs through the use of appropriate hardware and software protection domains, coupled with self-defence mechanisms, instrumentation, and fault-tolerance. Since the above methods will typically interfere with many legitimate operations (such as the installation of new software or the correction of an existing version) they need to be coordinated through carefully designed and executed security procedures. Unfortunately current practice in system administration often renders these methods useless. A large percentage of users typically administer their personal workstations on their own, in most cases exercising the full rights of the system administrator, without sufficient training and diligence.
Therefore, as a secondary line of defence, detection measures are often employed to locate virus instances and infections. Two often used detection measures involve either the comparison of the system's programs against known-good versions (typically condensed in the form of a checksum or a cryptographically secure signature [8]) or the comparison of files against patterns of known viruses. Since the first method depends on a known-clean system and can not be used to check software of unknown origin, the second, scanning, method is the one most commonly employed. A number of software vendors provide virus-scanning software that can search new and existing system files for patterns of all known viruses. The vendors regularly distribute updated versions of the virus patterns to keep the virus detection process up-to-date.
Virus writers however, have developed a series of countermeasures. Even early academic examples of viral code were cleverly engineered to hinder the detection of the virus [9]. Since the actual task of writing a virus is relatively simple [10], [11] modern virus code focuses on employing platform independence, stealth, effective replication, and detection countermeasures. Three pattern-matching detection countermeasures typically employed are the encryption of the virus body with a variable cryptographic key, the polymorphic generation of the decryption routine using equivalent code instructions, and, more recently, the metamorphic generation of the whole virus body through the addition, removal, permutation, and substitution of code sequences. Viruses that employ these techniques, such as W32/Simile [12] can be very difficult to identify. In the following section we establish that reliably detecting instances of such viruses is a problem of NP-complete complexity.
A virus is formally defined [13] by reference to a Turing Machine [14]
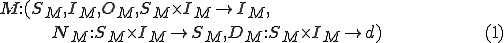
with a given set of states 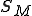 , set of input symbols
, set of input symbols 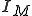 , and maps
, and maps  that, based on its current state
that, based on its current state 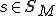 and input symbol
and input symbol 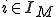 coming from a semi-infinite tape, determine: the output symbol
coming from a semi-infinite tape, determine: the output symbol 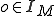 to write on the tape, the machine's next state
to write on the tape, the machine's next state 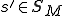 , and the tape's motion
, and the tape's motion 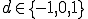 .
.
Given the machine 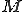 , a sequence of tape symbols
, a sequence of tape symbols 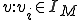 can be considered as a virus for that machine iff, processing the sequence
can be considered as a virus for that machine iff, processing the sequence  at time (sequence point)
at time (sequence point) 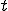 implies that at a future time point
implies that at a future time point 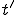 a sequence
a sequence 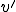 - not overlapping with - will exist on the tape, and that the sequence will have been written by at a point
- not overlapping with - will exist on the tape, and that the sequence will have been written by at a point 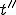 lying between and :
lying between and :
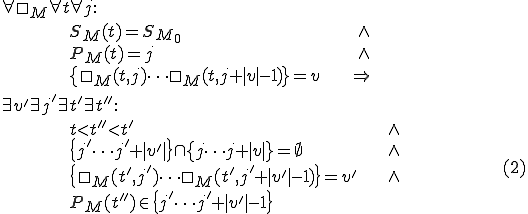
where
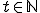 stands for the number of times the machine has performed its basic operation - "move"
stands for the number of times the machine has performed its basic operation - "move"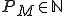 represents the machine's tape cell position number at time
represents the machine's tape cell position number at time 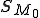 is the machine's initial state
is the machine's initial state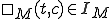 represents the content of cell
represents the content of cell  at time
at time Note that in the original seminal reference [13] the above virus definition appears in the context of a viral set 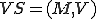 : a tuple consisting of a Turing Machine and a set of symbol sequences
: a tuple consisting of a Turing Machine and a set of symbol sequences 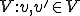 . From the virus definition it is clear that the notion of a virus is intimately associated with its interpretation in a given context - environment. It has been shown [13] that "any self-replicating tape symbol sequence is a one element
. From the virus definition it is clear that the notion of a virus is intimately associated with its interpretation in a given context - environment. It has been shown [13] that "any self-replicating tape symbol sequence is a one element 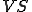 , that there are countably infinit s and non s, that machines exist for which all tape sequences are viruses and for which no tape sequences are viruses, and that any finite sequence of tape symbols is a virus with respect to some machine." The same reference also proves that in the general case determining whether a given tuple
, that there are countably infinit s and non s, that machines exist for which all tape sequences are viruses and for which no tape sequences are viruses, and that any finite sequence of tape symbols is a virus with respect to some machine." The same reference also proves that in the general case determining whether a given tuple 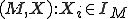 is viral is an undecidable problem (i.e. that there is no algorithm that can reliably detect all viruses) through a reasoning similar to that employed to prove the undecidability of the Halting Problem [14]. Other researchers have shown that there are also virus types (viruses that evolve to contain an instance of the virus detection program) that can not be detected by any error-free algorithm [15].
is viral is an undecidable problem (i.e. that there is no algorithm that can reliably detect all viruses) through a reasoning similar to that employed to prove the undecidability of the Halting Problem [14]. Other researchers have shown that there are also virus types (viruses that evolve to contain an instance of the virus detection program) that can not be detected by any error-free algorithm [15].
As is often the case, current practice differs from theory. Typical pattern based virus detection software scans a (relatively) known environment (processor architecture and operating system) to locate one of several (thousands in practice) a-priori known viruses. In the following paragraphs we will therefore establish the complexity of the more restricted problem of locating an instance of a known finite length virus in a given execution environment. For instance, the virus programs we provide in the appendices are only viral in the context of compilation and execution following the rules of Haskell and ANSI C/POSIX, respectively.
The complexity of detecting a known fixed virus pattern of length in a program of length 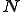 is harnessed by the Boyer-Moore string-searching algorithm [16] which never uses more than
is harnessed by the Boyer-Moore string-searching algorithm [16] which never uses more than 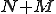 steps and under many circumstances (a small pattern and a large alphabet) can use about
steps and under many circumstances (a small pattern and a large alphabet) can use about 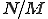 steps. Unfortunately, as we saw in the previous section, virus writers are seldom thus accommodating; fixed search patterns are not any more a viable virus detection method. We will prove that the problem of reliably identifying a bounded-length mutating virus is NP-complete. Our proof is based on showing that a virus detector
steps. Unfortunately, as we saw in the previous section, virus writers are seldom thus accommodating; fixed search patterns are not any more a viable virus detection method. We will prove that the problem of reliably identifying a bounded-length mutating virus is NP-complete. Our proof is based on showing that a virus detector 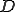 for a certain virus strain
for a certain virus strain 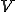 can be used to solve the satisfiability problem, which is known to be NP-complete [17]. (This approach works in the same way for any similar NP-complete problem; the satisfiability of the problem we are examining is not a special case.)
can be used to solve the satisfiability problem, which is known to be NP-complete [17]. (This approach works in the same way for any similar NP-complete problem; the satisfiability of the problem we are examining is not a special case.)
The virus is a mutating self-replicating program. We assume that the virus detector can reliably determine in P-time whether a given candidate program 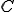 is a mutation of the virus . We will use the virus detector as an oracle for determining the satisfiability of an -term boolean formula
is a mutation of the virus . We will use the virus detector as an oracle for determining the satisfiability of an -term boolean formula 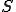 of the following type:
of the following type:
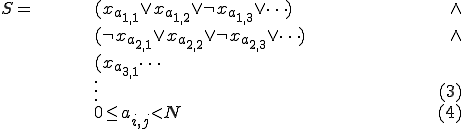
and thereby show that a P-time reliable virus detector is equivalent to a P-time solution to the satisfiability problem.
We will use the satisfiability formula to create a virus archetype 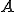 and a possible instance of a virus phenotype
and a possible instance of a virus phenotype 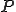 .
.
The virus is a triple

where
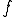 is the virus processing and replication function
is the virus processing and replication function is a boolean value indicating whether an instance of the virus has found a solution to is an integer encoding the candidate values for
is a boolean value indicating whether an instance of the virus has found a solution to is an integer encoding the candidate values for The function maps a triple 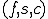 into a new triple
into a new triple 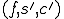 and is defined as follows:
and is defined as follows:
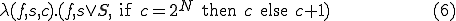
Each term 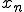 is calculated from through the expression
is calculated from through the expression
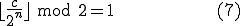
A new generation of the virus is generated by applying to the current generation.
Expressed in words, each new virus generation
by extracting successive boolean value combinations from until it reaches 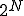 evaluation to the next generation
evaluation to the next generationWe can now ask whether the virus archetype

will ever result in a virus mutation phenotype

that is whether one of the virus mutations will satisfy .
We have thus proven that a reliable virus detector operating in P-time can be used as a P-time satisfiability oracle and that therefore reliable virus detection is NP-complete.
As an example for the operation of the virus consider the satisfiability of the formula

The virus replication function - after omitting for simplicity of expression the conditional, which only serves to limit the number of virus mutations - will be:
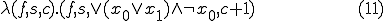
the corresponding archetype :
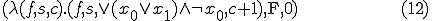
and the phenotype indicating satisfiability:
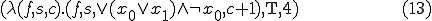
This particular virus will generate a mutation - and there by indicate that is satisfiable - in four generations through the following sequence:
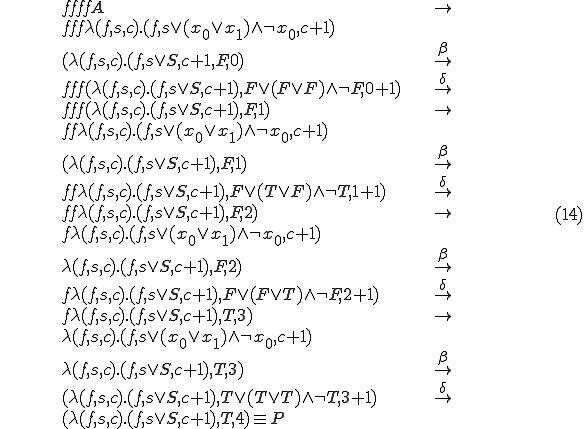
The creation of metamorphic viruses is a relatively recent phenomenon that places a considerable threat on our information system infrastructures. From a theoretical point of view, the viruses bear remarkable similarities to the virus we have examined and the examples depicted in this paper's appendices. Virus detection programs however need not be 100% correct. Users can tolerate the (typically remote) possibility of some "noise" (false positives), because in practice it is quite rare for a non-viral program to match the detection pattern of a known virus. As an example, a virus detector that detected this paper's viruses and also detected as a virus all triplets of the form 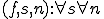 (even cases where is a non-satisfiable formula and is true) would probably be tolerated as a functioning "good-enough" virus detector, although strictly speaking it detects some false positives. Such a virus detector can be implemented to terminate in linear time and is not NP-complete.
(even cases where is a non-satisfiable formula and is true) would probably be tolerated as a functioning "good-enough" virus detector, although strictly speaking it detects some false positives. Such a virus detector can be implemented to terminate in linear time and is not NP-complete.
Thus, given the difference between the theoretically perfect detection (which is in the general case undecidable, and for known viruses, as we demonstrated, NP-complete) and the practically sufficient identification (which is the basis for a number of working virus scanner implementations) two questions arise.
An interesting phenomenon affecting the above topics concerns the currently permeable boundary between code and data. Buffer overflow attacks [18] are based on data that overwrites a carelessly written program's return stack address lying at the end of a data buffer to cause the program to execute part of that data. This renders all data files (documents, images, music, video - many of them highly compressed) stored on a computer potential carriers of viral code and dramatically increases the data a virus detector has to scan and discriminate. Few viruses currently propagate through buffer overflows; these weaknesses have traditionally been mainly exploited by worms and Trojan horses [19]. However, once such viruses are released, the current virus detection approach will come under increasing strain, faced with the short pattern vectors of mutating viruses and orders of magnitude more data to scan; as an example a 18GB disk filled with MP3 files is likely to contain any 4-byte (virus) pattern. In the medium and long term, hardening our security defences and developing software, procedures, and work practices that will stem the spread of malware seem to be the only reasonable alternatives.
The following code defines the virus replication function and the respective archetype and candidate phenotype, for determining the satisfiability of the expression
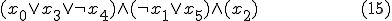
The satisfiability function candidate values are encoded using Haskell's arbitrary precision integers.
The following code is the virus archetype, again for determining the satisfiability of the expression (15). The satisfiability function candidate values are encoded as elements of the array x.
The candidate virus phenotype begins as follows:
The author acknowledges the valuable suggestions of the anonymous referees on an earlier version of this paper. The publication of this work was supported by the IST project mEXPRESS (IST-2001-33432), which is funded in part by the European Commission.
PLACE PHOTO HERE
Diomidis Spinellis holds an MEng in Software Engineering and a PhD in Computer Science both from Imperial College (University of London, UK). Currently he is an Assistant Professor at the Department of Management Science and Technology at the Athens University of Economics and Business, Greece. He is the author of the book "Code Reading: The Open Source Perspective" (Addison Wesley, 2003) and more than 60 journal papers and conference presentations. He has contributed software to the BSD Unix distribution, the X-Windows system, and is the author of a number of open-source software packages, libraries, and tools. His research interests include Information Security, Software Engineering, and Ubiquitous Computing.
Dr. Spinellis is a member of the ACM, the IEEE Computer Society, the Greek Computer Society, the Technical Chamber of Greece, and a founding member of the Greek Internet User's Society. He is a co-recipient of the Usenix Association 1993 Lifetime Achievement Award.
1 IEEE Transactions on Information Theory, 49(1):280-284, January 2003.
2 This is a machine-readable rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the reference in the previous footnote. This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.
[Back to index] [Comments (0)]