
Константин Климентьев
http://www.uinc.ru/
2000
Хотя официально фирма Microsoft информацией по этой теме мало с кем делилась, и даже одно время пыталась препятствовать ее распространению, все же нельзя сказать, что эта информация закрыта. Ей на самом деле владеют многие. Без этой информации не существовали бы такие продукты, как антивирусы KAV и DrWEb, переводчик Stylus, пакет 1С:Предприятие и т.п.
Сейчас в Интернете ее вполне достаточное количество, просто она разбросана мелкими порциями по разным малоизвестным источникам, и, что еще более неприятно, озаглавлена совсем не так, как хотелось бы нам. К сожалению, это как раз тот случай, о котором предупреждал незабвенный Козьма Прутков: на клетке слона частенько можно встретить надписи "буйвол", "мышь", "муравей", "динозавр", но только не "слон".
Цель этой статьи - попытаться собрать наиболее важные осколки информации в одно целое и указать места, где они валяются россыпью.
Файлы документов MS WinWord с расширением .DOC представляют собой сложные объекты, организованные по правилам структурированного хранилища (structured storage). Фактически, структурированное хранилище - это отдельная файловая система от Microsoft, примерно такая же, как FAT или NTFS. Используют ее очень многие Windows-приложения разных производителей, функционирующие в рамках технологий OLE/COM/ActiveX. Вот (очень неполный!) список расширений файлов, устроенных по правилам структурированного хранилища, которые я обнаружил на своем компьютере: .DOC, .DOT, .XLS, .XLA, .WIZ, .CAG, .FLA, .PPT, .MD и пр.
Сам же дисковый файл, хранящий внутри себя структурированное хранилище, называется "файл-документ" (docfile) или "составной файл" (compound file). Первый термин применялся во времена OLE 1, второй появился в середине 90-х годов вместе с OLE 2, сейчас они обычно используются как синонимы.
В OLE существует еще понятие "составной документ" (compound document), но этот термин обозначает абстрактный подкласс хранилищ особого вида... в-общем, это уже ария несколько из другой оперы.
Внутри составной файл состоит из следующих элементов:
Еще в литературе про OLE можно встретить термин "корневое хранилище" (root storage). Нетрудно сообразить, что он на самом деле означает всего лишь корневой каталог, т.е. главный каталог в составном файле. Фактически, так оно и есть. Но в литературе этот термин иногда используется в качестве синонима для составного файла и файл-документа, ведь они без корневого каталога не могут существовать, также как и он без них. Ну что ж, будем иметь это в виду.
Наконец, потоки (streams), на которые имеются ссылки в корневом хранилище (root storage), могут называться "наборы свойств" (property sets). На самом деле, так имеют право наименоваться не все потоки (streams), а только те из них, кто организован особым родом: имеют стандартизованный заголовок, разбиты на специфические разделы и т.п. Для нас это не слишком важно.
Разобраться в теринологических хитросплетениях мне помогла книжка: Харрис Л. Освой самостоятельное программирование OLE за 21 день. - М.: Бином, 1995.-462 с.
Microsoft предоставляет мощные средства для работы в рамках технологии OLE, они сконцентрированы в библиотеках OLE2.DLL (для 16-разрядных приложений) и OLE32.DLL (для 32-разрядных приложений). В принципе, к ним можно обращаться из любой системы программирования (например, из MS VB и даже из языка ассемблера), использовав традиционный механизм GetModuleHandle/GetProcAddress. Но проще всего это делать из MS VC или Borland C/C++. По крайней мере, все примеры из этой статьи компилировались при помощи Borland C/C++ v5.01.
Итак, в довольно объемной и сложной библиотеке OLE32.DLL для нас с точки зрения темы статьи интересны около дюжины API- функций, позволяющих создавать и открывать составные файлы в различных режимах, обращаться к их каталогам и т.п. Рассмотрим некоторые из них.
HRESULT StgCreateDocfile (WCHAR *ИмяФайла,
DWORD ФлагиДоступа,
DWORD НеИспользуется,
IStorage **Интерфейс);
Обычно для параметра ФлагиДоступа используется конкатенация из битов STGM_CREATE (создать новый составной файл), STGM_READ (разрешить чтение), STGM_WRITE (разрешить запись) или STGM_READWRITE (разрешить чтение и запись). Но можно указать STGM_CONVERT, это якобы позволяет преобразовывать "сырые" данные в структурированное хранилище, помещая их в поток с предопределенныи именем CONTENTS.
HRESULT StgOpenStorage (WCHAR *ИмяФайла,
IStorage *УжеОткрытыйИнтерфейс,
DWORD ФлагиДоступа,
SNB МаскаИсключения,
DWORD НеИспользуется,
IStorage **Интерфейс);HRESULT StgIsStorageFile(WCHAR* ИмяФайла)
Функции StgCreateDocfile и StgOpenStorage требуют имя дискового файла (например, L"C:\FILE.DOC"), а возвращают в последнем параметре интерфейс доступа - т.е. указатель на объект класса IStorage, свойства и методы которого позволяют манипулировать с элементами структуры уже открытого или созданного составного документа (физически это - просто массив адресов).
Дальше кратко описываются некоторые, наиболее интересные методы этого интерфейса.
HRESULT CreateStorage(wchar_t *ИмяПодкаталога,
DWORD ФлагиДоступа,
DWORD НеИспользуется1,
DWORD НеИспользуется2,
IStorage **ОткрытыйОбъект);HRESULT OpenStorage(wchar_t *ИмяПодкаталога,
IStorage *УжеОткрытыйОбъект
DWORD ФлагиДоступа,
SNB ИменаПотоков,
DWORD НеИспользуется,
IStorage **ОткрытыйОбъект);ULONG Release(void);
HRESULT EnumElements(DWORD НеИспользуется1,
void НеИспользуется2,
DWORD НеИспользуется3,
IEnumSTATSTG **ИнтерфейсПеречисления);
Возвращает новый интерфейс к объекту-перечислителю, который обладает методами:
HRESULT CreateStream(wchar_t * ИмяПотока,
DWORD ФлагиДоступа,
DWORD НеИспользуется1,
DWORD НеИспользуется2,
IStream **ОткрытыйПоток);HRESULT OpenStream(const wchar_t *ИмяПотока,
void *НеИспользуется1,
DWORD ФлагиДомтупа,
DWORD НеИспользуется2,
IStream **ОткрытыйПоток);HRESULT Write(void *Буфер,
ULONG Размер,
ULONG *РеальноЗаписано);HRESULT Read(void *Буфер,
ULONG Размер,
ULONG *РеальноПрочитано);HRESULT RenameElement(wchar_t *СтароеИмя,
wchar_t *НовоеИмя);Фактически, сервисных методов гораздо больше. Например, существует большой набор методов для работы с lock-bytes, но он нам в контексте статьи не слишком актуален.
Теперь рассмотрим примерчик работы с составным файлом через OLE API, а именно - рекурсивный просмотр дерева заключенных внутри объектов:
// Рекурсивный сканер docfile. (с) Климентьев К., Самара 2002
#include "windows.h"
#include "ole2.h"
#include "iostream.h"
#include "stdio.h"
int level=0;
walk(char *s, LPSTORAGE ls)
{
OLECHAR FileName[256]; LPENUMSTATSTG lpEnum=NULL;
LPSTORAGE pIStorage=NULL; LPSTORAGE pIStorage2=NULL;
ULONG uCount; STATSTG stat; int i;
if (!ls) {
mbstowcs(FileName, s, 256); wprintf(L"[%s]\n", FileName);
StgOpenStorage(FileName, NULL,
STGM_READ|STGM_SHARE_EXCLUSIVE,
NULL,0,&pIStorage);
walk("", pIStorage);
}
else {
ls->EnumElements(0,NULL,0,&lpEnum);
if (lpEnum)
while (lpEnum->Next(1,&stat,&uCount)==S_OK) {
for (i=0;i<level;i++) wprintf(L" ");
wprintf(L"%d: %s\n", stat.type, (LPSTR)stat.pwcsName);
if (stat.type==STGTY_STORAGE) {
ls->OpenStorage(stat.pwcsName, NULL,
STGM_READ|STGM_SHARE_EXCLUSIVE,
NULL, 0, &pIStorage2);
level++;
walk("", pIStorage2);
level--;
}
};
ls->Release();
}
}
int main(int argc, char* argv[]) {
if (argc>1) walk(argv[1],NULL);
}
Создадим в Word 97/2000/XP пустой DOC-файл без текста и напустим на него нашу программу. Мы увидим примерно следующее:
[word97.doc] 2: 1Table 2: \1CompObj 1: ObjectPool 2: WordDocument 2: \5SummaryInformation 2: \5DocumentSummaryInformation
Для DOC-файла в формате Word 6/7 (его можно создать, например, при помощи Wordpad) картинка будет попроще:
[word6.doc] 2: \1CompObj 2: WordDocument
Примерно так, как описано в этом разделе, устроены популярный FAR-плагин DocFile Browser Игоря Павлова и утилита OLE2View из MS Visual C/С++.
Если хотите подробностей, то рекомендую:
Широко известен народный персонаж по имени Чукча, который служил "писателем" и по этой причине не считал для себя нужным учиться читать. Наверное, имеются автомобилисты, которые никогда не заглядывали под капот своего четырехколесного друга. Не исключено, что существуют нежно любящие друг друга супруги, которые ни разу в жизни... гм... надеюсь, мы к их числу не относимся?
Давайте же приоткроем "кошмарную тайну кровавой фирмы Microsoft": посмотрим на составной файл невооруженными глазками и пощупаем его голыми ручками. Впрочем, "программисты", которые умеют только кликать по иконкам и таскать мышом картинки между окошкам, могут этот раздел с чистой совестью пропустить.
Составной файл состоит из целого числа "больших блоков" (big blocks), размер каждого из которых соответствует одному дисковому сектору, т.е. 512 байт. Поэтому, в отличие от англоязычной документации, мы будем называть их просто секторами. Все сектора в файле пронумерованы следующим образом: -1, 0, 1, 2... и т.д.
Сектор с номером -1 содержит заголовок составного файла:
struct DOC_FILE_HEADER
{
DWORD Сигнатура; // +00h - "магическое" число E011CFD0h
DWORD КодВерсииOLE; // +04h - "магическое" число E11AB1A2h
DWORD НеИспользуется1[9];
DWORD РазмерBBD; // +2Ch - количество секторов в BBD
DWORD НачалоКаталога; // +30h - стартовый сектор каталога
DWORD НеИспользуется2[2];
DWORD НачалоSBD; // +3Сh - стартовый сектор SBD
DWORD РазмерСектора; // +40h - обычно имеет значение 1
DWORD НеИспользуется3[2];
DWORD НачалоBBD; // +4Ch - стартовый сектор BBD
};
Примечание. Есть предположние, что по смещению 40h располагается поле, описывающее размер сектора. В подавляющем большинстве DOC-файлов длиной до 1 Мб в этом поле содержится значение 1 (т.е. размер сектора равен 512), но изредка встречается 2 (т.е. размер сектора равен 1024). Вероятно, возможны 3, 4, и так далее. В этом случае лучше говорить не о "секторах", но о "кластерах". Но идеология организации составного файла от этого не меняется.
Теперь очень легко проверить, организован ли какой-нибудь файл по правилам структурированного хранилища: достаточно проверить его первые 4 байта. Они должны быть: 0D0h, 0CFh, 11h, E0h.
Все остальное, не занятое заголовком, пространство составного файла разбито на четыре (не обязательно непрерывных!) области:
Я не случайно пошел вразрез с англоязычной терминологией. Дело в том, что структура, о которой пойдет речь в этом разделе, является ничем иным, как FAT - File Allocation Table, т.е. таблицей секторов, занимаемых файлом (вернее, занимаемых потоком или каким-либо другим объектом). А оригинальный термин "BBD - big blocks depot" может только ввести в заблуждение.
FAT - она и в Африке FAT. Это последовательный список 4-байтовых "строчек", каждая из которых соответствует одному сектору. Нулевая запись соответствует сектору с номером 0 (т.е. 512-байтовому сектору, начинающемуся в файле по абсолютному смещению 200h), первая - сектору с номером 1 (смещение 400h) и т.д. Еще раз напомним: сектора нумеруются с -1, т.е. самый первый сектор составного файла в этой таблице просто не упоминается!
Содержимое 4-байтовой строчки FAT может быть выбрано из следующих вариантов:
Если мы знаем номер стартового сектора для какого-либо объекта (например, для потока), мы легко можем вытянуть всю цепочку принадлежащих ему секторов. Вот конкретный пример, фрагмент дампа файла, содержащий начало FAT:
01 00 00 00 - 02 00 00 00 - 05 00 00 00 - 06 00 00 00 07 00 00 00 - 03 00 00 00 - FF FF FF FE - 08 00 00 00 FF FF FF FE - FF FF FF FD - FF FF FF FF - FF FF FF FF
Давайте выпишем значения "строчек" таблицы в более удобной для глаза форме и в скобочках каждой строчке припишем ее номер:
(00) 01
(01) 02
(02) 05
(03) 06
(04) 07
(05) 03
(06) -2
(07) 08
(08) -2
(09) -3
(0A) -1
(0B) -1
Допустим, известно, что стартовый сектор потока имеет значение 0, т.е. этот сектор заведомо уже принадлежит потоку. В нулевой строчке читаем: следующий сектор потока имеет номер 1. Переходим к строчке номер 1, и т.д., окончательно получаем цепочку номеров секторов: {0, 1, 2, 5, 3, 6}. Именно так, именно в таком порядке и разместил MS Word фрагменты какого-то потока внутри составного файла!
Кстати, обратите внимание на вклинившиеся куски какого-то другого объекта, живущего в секторах {4, 7, 8} и на пустые сектора с адресами 0A и 0B. Вероятно, это свидетельство того, что над документом долго и мучительно работали: многократно удаляли и вставляли фрагменты текста, рисунки, формулы и т.п.
Осталось выяснить, как же до этой FAT добраться. Смотрим на заголовок составного файла: по смещению 4Ch живет адрес стартового сектора в составном файле, а количество этих секторов живет по смещению 2Ch. Сектора располагаются непрерывно.
Хранить множество малоразмерных объектов в 512-байтных секторах довольно нерационально. Поэтому в структуре составного файла предусмотрена возможность размещать данные в маленьких, 64-байтовых "блочках" (small blocks).
Идеология расположения 64-байтовых "блочков" мало отличается от рассмотренной нами в предыдущем разделе для 512- байтовых "больших блоков". Под них выделяются область составного файла, отдельные "блочки" в которой пронумерованы с 0.
Но область "блочков" носит подчиненный характер. Она описана в "главной" FAT как отдельный объект, под который отведена отдельная цепочка секторов. Для нее же существует отдельная FAT, которая тоже фактически представлена цепочкой 512-байтовых секторов в "главной" FAT.
Числа в строчках "маленькой" FAT соответствуют не абсолютным номерам 512-байтовых секторов, а относительным номерам 64-байтовых "блочков" внутри своей области.
Местоположение стартового сектора FAT "блочков" берется из заголовка составного файла (смещение 3Сh), остальные можно вытянуть по цепочке в "главной" FAT. Не хватает только информации о том, где брать стартовый сектор области, распределенной под "блочки", но речь об этом пойдет в следующем разделе.
Кстати, область "блочков" в файле может просто отсутствовать.
Вопреки нашим предварительным предположениям, каталогов внутри составного файла не несколько, он - один единственный! Сей объект также представлен цепочкой секторов внутри "главной" FAT, а номер его стартового сектора можно найти в заголовке составного файла по смещению 30h.
Каталог состоит из 128-байтовых записей следующей структуры:
struct DIR_ENTRY
{
BYTE ИмяОбъекта[64]; // +00 - имя объекта в UNICODE
WORD РазмерИмени; // +40h - фактическая длина имени
BYTE ТипОбъекта; // +42h - 1,2,3 или 5
BYTE НеИспользуется1; // +43h
DWORD Предыдущий; // +44h - предыдущий объект
DWORD Следующий; // +48h - следующий объект
DWORD Первый; // +4Сh - первый подчиненный
DWORD НеИспользуется2[9]; // +50h
DWORD СтартСектор; // +74h - стартовый сектор объекта
DWORD РазмерОбъекта; // +78h - размер объекта в байтах
DWORD НеИспользуется3; // +7Сh
};
Хотя записи в каталогах обычно называются термином "entry" (вхождение), разработчики OLE решили (IMHO, напрасно!) взглянуть на них с точки зрения объектного подхода и назвали их (а также те объекты, которые они описывают) словом "property" (свойство). Остается только сокрушенно покачать головой по этому поводу и продолжать называть вещи пусть и "нелегальными", но более понятными именами.
Имя объекта записывается латинскими буквами и хранится в формате UNICODE, т.е. для того, чтобы перевести его в удобочитаемую форму, потребуется собрать вместе все нечетные байты. Имейте в виду: самый первый символ имени может оказаться "нечитабельным" и иметь значение, например, 05h ("трефы") или 01h ("рожица"). Не пугайтесь, это так и должно быть. Фактическая длина имени хранится в записи по смещению 40h.
Тип объекта описан байтом, хранящимся по смещению 42h:
Местоположение объекта задается номером его стартового сектора (см. смещение 74h), под которым его и нужно искать в FAT. А фактическая длина объекта (например, потока) располагается по смещению 78h. Необходимо иметь в виду: если длина объекта >= 1000h = 4096, то он располагается в больших 512- байтовых блоках (т.е. в секторах). В противном случае значение по адресу 74h указывает на стартовый "блочок" в области 64-байтовых "блочков". Сама эта область представлена в каталоге как "Root Entry", и искать ее следует в FAT больших блоков (даже если ее длина <4096) - вот она, недостававшая нам в предыдущем разделе информация!
Три поля по смещениям 44h, 48h и 4Сh описывают отношения страшинства между объектами. Для каталогов и подкаталогов (но не для потков!) в поле "Первый" хранится номер записи для какого-то своего дочернего объекта, которые, в свою очередь, имеют своих "Следующих" и т. д. Таким образом, все записи в каталоге упорядочиваются в виде дерева.
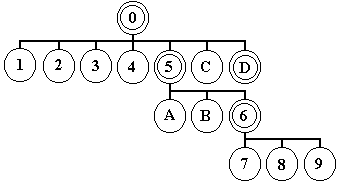
Вот дамп одной из записей в каталоге:
05 00 44 00-6F 00 63 00-75 00 6D 00-65 00 06 00 ..D.o.c.u.m.e.n 74 00 53 00-75 00 6D 00-6D 00 61 00-72 00 79 00 t.S.u.m.m.a.r.y 49 00 06 00-66 00 6F 00-72 00 6D 00-61 00 74 00 I.n.f.o.r.m.a.t 69 00 6F 00-6E 00 00 00-00 00 00 00-00 00 00 00 .i.o.n......... 38 00 02 01-02 00 00 00-04 00 00 00-FF FF FF FF 8.............. 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00 ............... 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00 ............... 00 00 00 00-10 00 00 00-00 10 00 00-00 00 00 00 ...............
Легко видеть, что:
А вот пример полного каталога:
# Имя Тип Пред След Перв Старт Разм 0 Root Entry 5 -1 -1 3 24 1440 1 \1Table 2 -1 -1 -1 8 1000 2 WordDocument 2 5 -1 -1 0 1000 3 \5SummaryInformation 2 2 4 -1 10 1000 4 \5DocumentSummaryInformation 2 -1 -1 -1 18 1000 5 Macros 1 1 C B 0 0 6 VBA 1 -1 -1 7 0 0 7 ThisDocument 2 9 8 -1 0 44D 8 _VBA_PROJECT 2 -1 -1 -1 12 AA5 9 dir 2 -1 -1 -1 3D 2A3 A PROJECTwm 2 -1 -1 -1 48 29 B PROJECT 2 6 A -1 49 151 C \1CompObj 2 -1 D -1 4F 6A D ObjectPool 1 -1 -1 -1 0 0
Попробуем выполнить упорядочивание. Начнем с узла "0" ("Root Entry"), его первым "сыном" является узел "3". Собрав воедино все узлы, связанные с узлом "0" и между собой, получим следующее множество: {1, 2, 3, 4, 5, С, D}. Оно образует первый уровень дерева.
На первом уровне присутствуют три объекта со статусом каталогов: "5" и "D". Дочерними объектами каталога "5" являются узел "B" и все связанные с ним объекты: {A, B, 6}. Каталог "D" не имеет дочерних объектов, т.е. он пуст. И так далее...
Можно написать несложный рекурсивный алгоритм, который построит желаемое дерево:
Итак, с составным файлом можно работать не только через OLE API, но и напрямую - например, из DOS-овской программы.
Данный раздел является существенно упорядоченным и несколько дополненным изложением статьи M. Schwartz. LAOLA file system. Единственный известный мне перевод этой статьи на русский язык можно найти, например, в материалах 4 -го выпуска электронного журнала "Земский Фершал".
Итак, мы подробно изучили с разных сторон множество действительно интересных вопросов, но... Следует признать, что основную тему статьи мы пока не раскрыли. В ближайшее же время попытаемся исправиться.
В Интернете можно найти немало ссылок на фирменные материалы "Microsoft Word 6.0 Binary File Format" и "Microsoft Word 97 Binary File Format", которые представляют собой огромные файлы, заполненные большим количеством малопонятных терминов, таблиц, списков и пр. Но название не совсем точно отражает действительность: на самом деле эти материалы описывают всего лишь структуру потока под названием "WordDocument". Продемонстрируем, что ничего совсем уж иррационального и трансцендентного в фирменной документации от Micrisoft нет.
Итак, поток "WordDocument" (в документации он называется "главным потоком" - main stream) начинается со своего собственного внутреннего заголовка, в котором мы упомянем всего несколько наиболее интересных для нас полей:
Смещение Длина Назначение Примечание
-----------------------------------------------
0h 2 Сигнатура Word6/Word97
2h 2 Код версии Word6/Word97
18h 4 Начало текста Word6/Word97
1Ch 4 Конец текста+1 Word6/Word97
34h 4 Длина текста+1 Word6
4Ch 4 Длина текста+1 Word97
Для документов, созданных в Word v6.0/7.0 или WordPad, сигнатура обычно равна 0A5DCh, а для Word97/2K/XP она равна 0A5ECh (все это верно по крайней мере для русских версий).
Если документ создан в MS WinWord, то текст обычно начинается по "круглым" смещениям (например, 200h или 300h), для прочих продуктов это не всегда выполняется (например, WordPad может разместить его по "треугольному" смещению 312h).
Текст для формата версий 6.0/7.0 представляет собой обычную последовательность однобайтовых символов в той или иной кодировке, а для более старших версий - в двухбайтовой кодировке UNICODE:
Символ Кодировка
-----------------
0-9 030h-039h
A-Z 041h-05Ah
a-z 061h-07Ah
А-Я 410h-42Fh
Ё 401h
а-я 430h-44Fh
ё 451h
Этой информации вполне достаточно, чтобы, например, извлечь из Word-документа текст. Производить обратную операцию несколько сложнее - для этого придется параллельно формировать таблицы описания свойств символов и абзацев.
Конечно, в статье рассмотрено далеко не все, что хотелось бы. И не всему вышенаписанному стоит беспрекословно доверять: например, весьма вероятно, что в случае огромных DOC-файлов структурированное хранилище может быть образовано из "секторов" с размерами большими, чем 512 байтов. Но теперь любознательный читатель может не только проверить информацию, но и продолжить собственные иследования двоичного формата документов WinWord.
Кому-то может показаться излишним приведенное выше подробное описание формата структурированных хранилищ. Но мне, например, оно сильно пригодилась, когда необходимо было вытаскивать текст из DOC-файлов, записанных на поцарапанную дискету. Функции OLE2 API в этой ситуации просто отказывались работать.
Кроме того, знание подробностей организации этого формата позволяет существенно ускорить работу с составным файлом: можно, например, напрямую искать в файле заголовочные сигнатуры отдельных компонентов (главного потока, вирусных макросов и т.п.) по смещениям, кратным 512.
Возможны и иные применения для информации, приведенной в этой статье. Желаю успехов!
После обнародования предыдущей версии этой статьи мне пришлось выслушать немало критики за ее неполноту, наличие многочисленых неточностей, и даже за то, что я дерзнул написать ее поперед тех "батьков", кто знает на эту тему гораздо больше, но шибко дорожит своей монополией на информацию.
К счастью, большинство читателей восприняли ту статью благожелательно. А правильней всех поступил С. Новодворский, который очень удачно углубил рассмотренную тему в своей собственной статье "Доступ к MD-файлам при помощи VBA", попутно исправив самые крупные мои неточности и дописав иллюстрирующий софт. Спасибо, Сергей, и так держать!
Итак, самая крупная неточность в моей статье касалась формата заголовка структурированного хранилища. Часть полей я тогда намеренно не описал (посчитав не важными), одно поле описал ошибочно, а о назначении некоторых полей в то время лишь смутно догадывался. Теперь я имею возможность привести новый, уточненный формат заголовка структурированного хранилища:
struct DOC_FILE_HEADER
{
DWORD Сигнатура; // +00h - "магическое" число E011CFD0h
DWORD КодВерсииOLE; // +04h - "магическое" число E11AB1A2h
DWORD НеИспользуется; // +08h
WORD НеИспользуется; // +0Ch
WORD РазмерСектора; // +0Eh - Log2(512)=9 (new!)
DWORD НеИспользуется; // +10h
DWORD НеИспользуется; // +14h
WORD НомерРевизии; // +18h - ? (new!)
WORD НомерВерсии; // +1Ah - ? (new!)
DWORD НеИспользуется; // +1Ch
DWORD НеИспользуется; // +20h
DWORD НеИспользуется; // +24h
DWORD НеИспользуется; // +28h
DWORD РазмерBBD; // +2Сh - количество секторов в BBD
DWORD НачалоКаталога; // +30h - стартовый сектор каталога
DWORD НеИспользуется; // +34h
DWORD НеИспользуется; // +38h
DWORD НачалоSBD; // +3Сh - стартовый сектор SBD
DWORD ПродолжениеSBD; // +40h - ? (new!)
DWORD ОкончаниеBBD; // +44h - стартовый сектор окончания BBD (new!)
DWORD НеИспользуется; // +48h
DWORD НачалоBBD; // +4Сh - стартовый сектор BBD
DWORD ПродолжениеBBD[108]; // +50h - адреса секторов продолжения BBD (new!)
};
Комментарии.
Не исключено, что и это еще не конец...
Выражаю благодарность Андрею Каримову, участнику проекта "Антивирус Stop!", в беседах с которым эта статья появилась на свет. Также ряд ценных критических замечаний сделал сотрудник "Лаборатории Касперского" Андрей Крюков.
Благодарю за внимание. С глубочайшим почтением и искреннейшей преданностию есмь, милостивые государи, Ваш покорный слуга
[Вернуться к списку] [Комментарии (0)]