
Guillaume Bonfante, Matthieu Kaczmarek, Jean-Yves Marion
Lecture Notes in Computer Science, volume 3722, pp.579-593. Springer, Oct 2005.
October 2005
 Download PDF (188.83Kb) (You need to be registered on forum)
Download PDF (188.83Kb) (You need to be registered on forum)We are concerned with theoretical aspects of computer viruses. For this, we suggest a new definition of viruses which is clearly based on the iteration theorem and above all on Kleene's recursion theorem. We show that we capture in a natural way previous definitions, and in particular the one of Adleman. We establish generic constructions in order to construct viruses, and we illustrate them by various examples. We discuss about the relationship between information theory and virus and we propose a defense against some kind of viral propagation. Lastly, we show that virus detection is 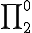 -complete. However, since we are able to deal with system vulnerability, we exhibit another defense based on controlling system access.
-complete. However, since we are able to deal with system vulnerability, we exhibit another defense based on controlling system access.
Computer viruses seem to be an omnipresent issue of information technology; there is a lot of books, see [13] or [16], discussing practical issues. But, as far as we know, there are only a few theoretical studies. This situation is even more amazing because the word "computer virus" comes from the seminal theoretical works of Cohen [4 - 6] and Adleman [1] in the mid-1980's. We do think that theoretical point of view on computer viruses may bring some new insights to the area, as it is also advocated for example by Filiol [8], an expert on computer viruses and cryptology. Indeed, a deep comprehension of mechanisms of computer viruses is from our point of view a promising way to suggest new directions on virus detection and defence against attacks. On theoretical approach to virology, there is an interesting survey of Bishop [2] and we aware of the paper of Thimbleby, Anderson and Cairns [10] and of Chess and White paper [3].
This being said, the first question is what is a virus? In his Phd-thesis [4], Cohen defines viruses with respect to Turing Machines. Roughly speaking, a virus is a word on a Turing machine tape such that when it is activated, it duplicates or mutates on the tape. Adleman took a more abstract formulation of computer viruses based on recursive function in order to have a definition independent from computation models. A recent article of Zuo and Zhou [21] completes Aldemans work, in particular in formalizing polymorphic viruses. In both approaches, a virus is a self-replicating device. So, a virus has the capacity to act on a description of itself. That is why Kleene's recursion theorem is central in the description of the viral mechanism.
This paper is an attempt to use computability and information theory as a vantage point from which to understand viruses. We suggest a definition which embeds Adelman's as well as Zuo and Zhou's definitions in a natural way.
A virus is a program 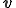 which is solution of the fixed point equation
which is solution of the fixed point equation
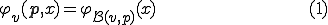
where 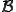 is a function which describes the propagation and mutation of the virus in the system. This approach has at least three advantages compared with others mentioned above. First, a virus is a program and not a function. Thus, we switch from a purely functional point of view to a more programming perspective one.
is a function which describes the propagation and mutation of the virus in the system. This approach has at least three advantages compared with others mentioned above. First, a virus is a program and not a function. Thus, we switch from a purely functional point of view to a more programming perspective one.
Second, we consider the propagation function, unlike others. So, we are able to have another look at virus replications. All the more so since corresponds also to a system vulnerability. Lastly, since the definition is clearly based on recursion theorem, we are able to describe a lot of kind of virus smoothly. To illustrate our words, we establish a general construction of trigger virus in Section 3.3.
The results and the organization of the paper is the following. Section 2 presents the theoretical tools needed to define viruses. We will focus in particular in the s-m-n theorem and the recursion theorem. In section 3, we propose a virus definition and we pursue by a first approach to self-duplication. Section 4 is devoted to Adlemans virus definition. Then, we explore another duplication methods by mutations. We compare our work with Zuo and Zhou definition of polymorphic viruses. Lastly, Section 6 ends with a discussion on the relation with information theory. From that, we deduce an original defense against some particular kind of viruses, see 6.3. The last Section is about virus search complexity which turns out to -complete. It is worth to mention that we conclude the paper on some research direction to study system flaws, see Theorem 14.
We are not taking a particular programming language but we are rather considering an abstract, and so simplified, definition of a programming language. However, we shall illustrate all along the theoretical constructions by bash programs. The examples and analogies that we shall present are there to help the reader having a better understanding of the main ideas but also to show that the theoretical constructions are applicable to any programming language.
We briefly present the necessary definitions to study programming languages in an independent way from a particular computational model. We refer to the book of Davis [7], of Rogers [15] and of Odifreddi [14].
Throughout, we consider that we are given a set 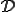 , the domain of the computation. As it is convenient, we take to be the set of words over some fixed alphabet. But we could also have taken natural numbers or any free algebra as domains. The size
, the domain of the computation. As it is convenient, we take to be the set of words over some fixed alphabet. But we could also have taken natural numbers or any free algebra as domains. The size 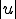 of a word
of a word 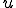 is the number of letters in .
is the number of letters in .
A programming language is a mapping 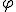 from
from 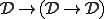 such that for each program
such that for each program 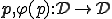 is the partial function computed by
is the partial function computed by  . Following the convention used in calculability theory, we write
. Following the convention used in calculability theory, we write  instead of
instead of 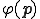 . Notice that there is no distinction between programs and data.
. Notice that there is no distinction between programs and data.
We write 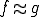 to say that for each
to say that for each 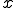 , either
, either 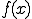 and
and 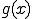 are defined and
are defined and 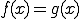 or both are undefined on .
or both are undefined on .
A total function 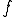 is computable wrt if there is a program such that
is computable wrt if there is a program such that 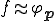 . If is a partial function, we shall say that is semi-computable. Similarly, a set is computable (resp. semi-computable) if its characteristic function is computable (semi-computable).
. If is a partial function, we shall say that is semi-computable. Similarly, a set is computable (resp. semi-computable) if its characteristic function is computable (semi-computable).
We also assume that there is a pairing computable function (_,_) such that from two words and 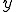 of , we form a pair
of , we form a pair 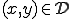 . A pair
. A pair 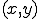 can be decomposed uniquely into and by two computable projection functions. Next, a finite sequence
can be decomposed uniquely into and by two computable projection functions. Next, a finite sequence 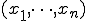 of words is built by repeatedly applying the pairing function, that is
of words is built by repeatedly applying the pairing function, that is 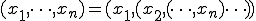 .
.
So, we won't make any longer the distinction between a n-uple and its encoding. Every function is formally considered unary even if we have in mind a binary one. The context will always be clear.
It is worth to mention that the pairing function may be seen as an encryption function and the projections as decryption function.
Following Uspenski [19] and Rogers [15], a programming language is acceptable if
, there is a program 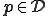 such that
such that 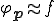 .
.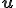 which satisfies that for each program
which satisfies that for each program 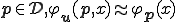 .
. such that
such that
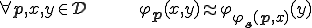
Of course, the function 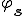 is the well-known s-m-n function written
is the well-known s-m-n function written 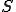 .
.
The existence of an acceptable programming language was demonstrated by Turing [18].
Kleene's Iteration Theorem yields a function which specializes an argument in a program. The self-application that is 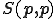 corresponds to the construction of a program which can read its own code . By analogy with bash programs, it means that the variable
corresponds to the construction of a program which can read its own code . By analogy with bash programs, it means that the variable $0 is assigned to the text, that is , of the executed bash file.
We present now a version of the second recursion theorem which is due to Kleene. This theorem is one of the deepest result in theory of recursive function. It is the cornerstone of the paper that is why we write the proof. We could also have presented Rogers's recursion theorem but we have preferred to focus on only one recursion theorem in order not to introduce any extra difficulties. It is worth also to cite the paper [11] in which the s-m-n function and the recursion theorem are experimented;
Theorem 1 (Kleene's second recursion Theorem). If 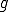 is a semicomputable function, then there is a program
is a semicomputable function, then there is a program  such that
such that

Proof. Let be a program of the semi-computable function 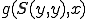 . We have
. We have
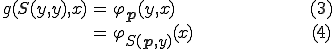
By setting 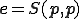 , we have
, we have
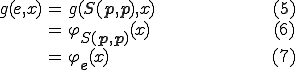
A virus may be thought of as a program which reproduces, and executes some actions. Hence, a virus is a program whose propagation mechanism is described by a computable function . The propagation function searches and selects a sequence of programs 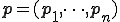 among inputs
among inputs 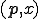 . Then, replicates the virus inside . In other words, is the vector which carries and transmits the virus to a program. On the other hand, the function can be also seen as a flaw in the programming environment. Indeed, is a functional property of the programming language which is used by a virus to enter and propagate into the system. We suggest below an abstract formalization of viruses which reflects the picture that we have described above.
. Then, replicates the virus inside . In other words, is the vector which carries and transmits the virus to a program. On the other hand, the function can be also seen as a flaw in the programming environment. Indeed, is a functional property of the programming language which is used by a virus to enter and propagate into the system. We suggest below an abstract formalization of viruses which reflects the picture that we have described above.
Definition 2. Assume that is a semi-computable function. A virus wrt is a program such that for each and in ,
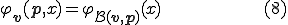
The function is called the propagation function of the virus .
Throughout, we call virus a program, which satisfies the above definition.
As we have said above, we make no distinction between programs and data. However we write in bold face words of , like 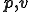 , which denote programs. On the other hand, the argument does not necessarily denote a data. Nevertheless, in both cases, or refer either to a single word or a sequence of words. (For example
, which denote programs. On the other hand, the argument does not necessarily denote a data. Nevertheless, in both cases, or refer either to a single word or a sequence of words. (For example 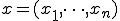 .)
.)
A distinctive feature of viruses is the self-reproduction property. This has been well developed for cellular automata from the work of von Neumann [20]. Hence, Cohen [4] demonstrated how a virus reproduces in the context of Turing machines.
We show next that a virus can copy itself in several ways. We present some typical examples which in particular illustrate the key role of the recursion Theorem.
We give a first definition of self-reproduction. (A second direction will be discussed in Section 5.) A duplication function 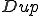 is a total computable function such that
is a total computable function such that 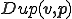 is a word which contains at least an occurrence of . A duplicating virus is a virus, which satisfies
is a word which contains at least an occurrence of . A duplicating virus is a virus, which satisfies 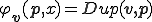 . The existence of duplicating viruses is a consequence of the following Theorem by setting
. The existence of duplicating viruses is a consequence of the following Theorem by setting 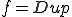 .
.
Theorem 3. Given a semi-computable function , there is a virus such that 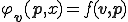
Proof. For set 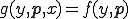 . Recursion Theorem implies that the semi-computable function has a fixed point that we call . We have
. Recursion Theorem implies that the semi-computable function has a fixed point that we call . We have 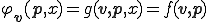 .
.
Next, let be a code of , that is  . The propagation function induced by is defined by
. The propagation function induced by is defined by  , since
, since
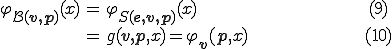
It is worth to say that the propagation function lies on the s-m-n function. The s-m-n function specializes the program to and , and thus it drops the virus in the system and propagates it. So, in some sense, the s-m-n function should be be considered as a flaw, which is inherent to each acceptable programming language.
To illustrate behaviors of duplicating viruses, we consider several examples, which correspond to known computer viruses.
A duplication function is a crushing if 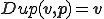 .
.
This basic idea is in fact the starting point of a lot of computer viruses. Most of the email worms use this methods, copying their script to many directories. The e-mail worm "loveletter" copies itself as "MSKernel32.vbs". Lastly, here is a tiny bash program which copies itself.
Suppose that 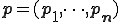 . Then, a virus is cloning wrt , if
. Then, a virus is cloning wrt , if 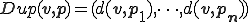 where
where 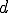 is a duplication function. A cloning virus keeps the structure of the program environment but copies itself into some parts. For example, we can think that is a directory and
is a duplication function. A cloning virus keeps the structure of the program environment but copies itself into some parts. For example, we can think that is a directory and 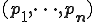 are the file inside. So a cloning virus infects some files in the directory.
are the file inside. So a cloning virus infects some files in the directory.
Moreover, a cloning virus should also verify that 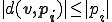 . Then, the virus does not increase the program size, and so the detection of such non-size increasing virus is harder.
. Then, the virus does not increase the program size, and so the detection of such non-size increasing virus is harder.
A cloning virus is usually quite malicious, because it overwrites existing program. A concrete example is the virus named "4870 Overwriting". The next bash program illustrates of a cloning virus.
A virus is an ecto-symbiote if it lives on the body surface of the program . For example, 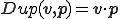 where
where  is the word concatenation.
is the word concatenation.
The following bash code adds its own code at the end of every file.
The computer virus "Jerusalem" is an ecto-symbiote since it copies itself to executable file (that is, ".COM" or ".EXE" files).
We establish a result which constructs a virus which performs several actions depending on some conditions on its arguments. This construction of trigger viruses is very general and embeds a lot of practical cases.
Theorem 4. Let 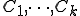 be
be 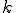 semi-computable disjoint subsets of and
semi-computable disjoint subsets of and 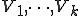 be semi-computable functions There is a virus which satisfies for all and , the equation
be semi-computable functions There is a virus which satisfies for all and , the equation
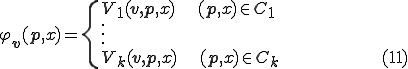
Proof. Define
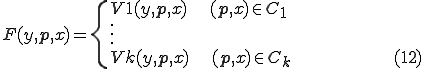
The function 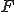 is computable and has a code such that
is computable and has a code such that 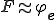 . Again, recursion Theorem yields a fixed point of which satisfies the Theorem equation. The induced propagation function is
. Again, recursion Theorem yields a fixed point of which satisfies the Theorem equation. The induced propagation function is 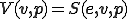
Adleman's modeling is based on the following scenario. For every program, there is an "infected" form of the program.
The virus is a computable function from programs to "infected" programs. An infected program has several behaviors which depend on the input . Adleman lists three actions. In the first (13) the infected program ignores the intended task and executes some "destroying" code. So it is why it is called injure. In the second (14), the infected program infects the others, that is it performs the intended task of the original, a priori sane, program, and then it contaminates other programs. In the third and last one (15), the infected program imitates the original program and stays quiescent.
We translate Adleman's original definition into our formalism.
Definition 5 (Adleman's viruses). A total computable function 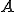 is said to be a -viral function (virus in the sense of Adleman) if for each
is said to be a -viral function (virus in the sense of Adleman) if for each 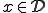 one of the three following properties holds:
one of the three following properties holds:
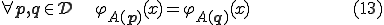
This first kind of behavior corresponds to the execution of some viral functions independently from the infected program.
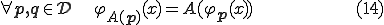
The second item corresponds to the case of infection. One sees that ny part of 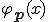 is rewritten according to .
is rewritten according to .
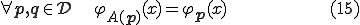
The last item corresponds to mimic the original program.
Our definition respects Adleman's idea and implies easily the original infection definition. In Adleman's paper, the infection definition is very closed to the crushing virus as they have defined previously. However, our definition of the infect case is slightly stronger. Indeed, there is no condition or restriction on the application of the A-viral function to to unlike Adleman's definition. Indeed, he assumes that 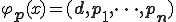 and that
and that 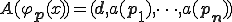 where
where  is a computable function which depends on A.
is a computable function which depends on A.
Theorem 6. Assume that is a A-virus. Then there is a virus which performs the same actions that .
Proof. Let be the code of , that is 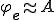 . There is a semi-computable function
. There is a semi-computable function 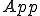 such that
such that 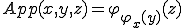 . Suppose that
. Suppose that 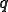 is the code of . Take
is the code of . Take 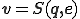 . We have
. We have
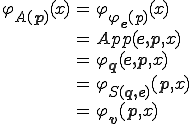
We conclude that the propagation function is 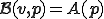
Until now, we have considered viruses which duplicate themselves without modifying their code. Now, we consider viruses which mutate when they duplicate. Such viruses are called polymorphic; they are common computer viruses. The appendix gives more "practical informations" about them.
This suggests a second definition of self-reproduction. A mutation function 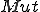 is a total computable function such that
is a total computable function such that 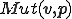 is a word which contains at least an occurrence of a virus
is a word which contains at least an occurrence of a virus 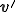 . The difference with the previous definition of duplication function in Subsection 3.2 is that is a mutated version of wrt .
. The difference with the previous definition of duplication function in Subsection 3.2 is that is a mutated version of wrt .
Theorem 3, and the implicit virus Theorem 4, shows that a virus is essentially a fixed point of a semi-computable function. In other word, a virus is obtained by solving the equation: 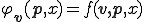 . And solutions are fixed points of . Rogers [15] established that a computable function has an infinite number of fixed points. So, a first mutation strategy could be to enumerate fixed points of . However, the set of fixed points of a computable function is
. And solutions are fixed points of . Rogers [15] established that a computable function has an infinite number of fixed points. So, a first mutation strategy could be to enumerate fixed points of . However, the set of fixed points of a computable function is 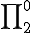 , and worst it is -complete for constant functions.
, and worst it is -complete for constant functions.
So we can not enumerate all fixed points because it is not a semicomputable set. But, we can generate an infinite number of fixed points.
To illustrate it, we suggest to use a classical padding function 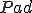 which satisfies
which satisfies
is a bijective function. and each , 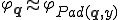 .
.Lemma 7. There is a computable padding function .
Proof. Take 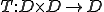 as a computable bijective encoding of pairs. Let
as a computable bijective encoding of pairs. Let 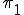 be first projection function of
be first projection function of 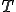 . Define
. Define 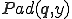 as the code of
as the code of 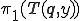 .
.
Theorem 8. Let be a computable function. Then there is a computable function 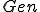 such that
such that
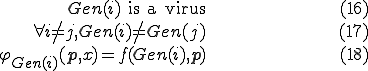
Proof. In fact, 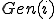 is the ith fixed point of wrt to a fixed point enumeration procedure. A construction of a fixed point enumeration procedure is made by padding Kleene's fixed point given by the proof of the recursion Theorem.
is the ith fixed point of wrt to a fixed point enumeration procedure. A construction of a fixed point enumeration procedure is made by padding Kleene's fixed point given by the proof of the recursion Theorem.
For this, suppose that is a program of the semi-computable function . We have
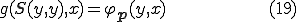
By setting 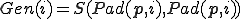 , we have
, we have
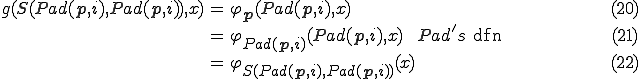
Remark 9. For a virus writer, a mutation function is a polymorphic engine, such as the well known "Dark Avenger". A polymorphic engine is a module which gives de ability to look different on replication most of them are encryptor, decryptor functions.
Polymorphic viruses were foreseen by Cohen and Adleman. As far as we know, Zuo and Zhou's are the first in [21] to propose a formal definition of the virus mutation process. They discuss on viruses that evolve into at most n forms, and then they consider polymorphism with an infinite numbers of possible mutations.
Definition 10 (Zuo and Zhou viruses). Assume that and 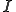 are two disjoint computable sets. A total computable function
are two disjoint computable sets. A total computable function 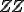 is a ZZ-viral polymorphic function if for all n and ,
is a ZZ-viral polymorphic function if for all n and ,
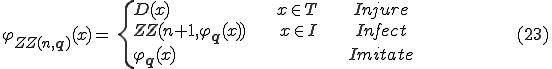
This definition is closed to the one of Adleman, where corresponds to a set of arguments for which the virus injures and is a set of arguments for which the virus infects. The last case corresponds to the imitation behavior of a virus. So, the difference stands on the argument n which is used to mutate the virus in the infect case. Hence, a given program has an infinite set of infected forms which are 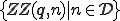 . (Technically,
. (Technically, 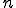 is an encoding of natural numbers into .)
is an encoding of natural numbers into .)
Theorem 11. Assume that is a ZZ-viral polymorphic function. Then there is a virus which performs the same actions that ZZ wrt a propagation function.
Proof. The proof is a direct consequence of implicit virus Theorem 4 by setting 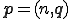 .
.
There are various way to define a mutation function. A crucial feature of a virus is to be as small as possible. Thus, it is much harder to detect it. We now revisit clone and symbiote virus definitions.
A compressed clone is a mutated virus such that 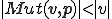 . A compression may use informations inside the program . There are several compression algorithms which perform such replications.
. A compression may use informations inside the program . There are several compression algorithms which perform such replications.
An endo-symbiote is a virus which hides (and lives) in a program. A spyware is a kind of endo-symbiote. For this, it suffices that
and from . That is, there are two inverse functions 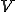 and
and 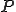 such that
such that 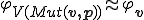 and
and 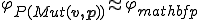
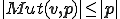
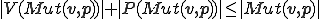
Both examples above show an interesting relationship with complexity information Theory. For this, we refer to the book of Li and Vitányi [12]. Complexity information theory leans on Kolmogorov complexity. The Kolmogorov complexity of a word wrt 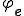 and knowing is
and knowing is 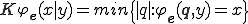 . The fundamental Theorem of Kolmogorov complexity theory yields: There is universal program such that for any program , we have
. The fundamental Theorem of Kolmogorov complexity theory yields: There is universal program such that for any program , we have 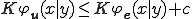 where
where  is some constant. This means that the minimal size of a program which computes a word wrt is
is some constant. This means that the minimal size of a program which computes a word wrt is 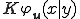 , up to an additive constant.
, up to an additive constant.
Now, suppose that the virus mutates to from . That is 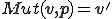 . An interesting question is then to determine the amount of information which is needed to produce the virus . The answer is
. An interesting question is then to determine the amount of information which is needed to produce the virus . The answer is 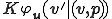 bits, up to an additive constant.
bits, up to an additive constant.
The demonstration of the fundamental Theorem implies that the shortest description of a word is made of two parts. The first part encodes the word regularity and the second part represents the "randomness" side of . And, we have 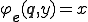 . Here, the program plays the role of an interpreter which executes in order to print . Now, let us decompose into two parts (i) an interpreter and (ii) a random data part such that
. Here, the program plays the role of an interpreter which executes in order to print . Now, let us decompose into two parts (i) an interpreter and (ii) a random data part such that 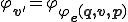 . In this construction, the virus introduces an interpreter for hiding itself. This is justified by the fundamental Theorem which says that it is an efficient way to compress a virus. In [9], Goel and Bush use Kolmogorov complexity to make a comparison and establish results between biological and computer viruses.
. In this construction, the virus introduces an interpreter for hiding itself. This is justified by the fundamental Theorem which says that it is an efficient way to compress a virus. In [9], Goel and Bush use Kolmogorov complexity to make a comparison and establish results between biological and computer viruses.
We suggest an original defense (as far as we know) against some viruses based on information Theory. We use the notations introduced in Section 6 about endo-symbiosis and Kolmogorov complexity.
Our defense prevents the system to be infected by endo-symbiote. Suppose that the programming environment is composed of an interpreter which is a universal program. We modify it to construct 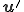 in such way that
in such way that 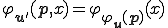 . Hence, intuitively a program for
. Hence, intuitively a program for 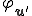 is a description of a program wrt
is a description of a program wrt 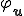 .
.
Given a constant , we define a -compression of a program as a program 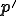 such that
such that 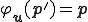 and
and 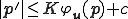 . Observe that
. Observe that 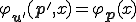 .
.
Now, suppose that is an endo-symbiote. So, there is a mutation function and two associated projections et . We have by definition of endo-symbiotes that 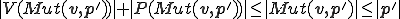 . By definition of , we have
. By definition of , we have 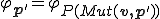 . As a consequence,
. As a consequence, 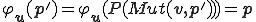 . So,
. So, 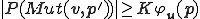 . Finally, the space
. Finally, the space 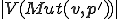 to encode the virus is bounded by . Notice that it is not difficult to forbid to execute programs which have less than bits. In this case, no endo-symbiote can infect . Therefore, -compressed programs are safe from attack by endo-symbiotes.
to encode the virus is bounded by . Notice that it is not difficult to forbid to execute programs which have less than bits. In this case, no endo-symbiote can infect . Therefore, -compressed programs are safe from attack by endo-symbiotes.
Of course, this defense strategy is infeasible because there is no way to approximate the Kolmogorov complexity by mean of a computable function. In consequence, we can not produce -compressed programs. However, we do think this kind of idea shed some light on self-defense programming systems.
Let us first consider the set of viruses wrt a function . It is formally given by 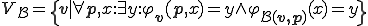 . As the formulation of
. As the formulation of 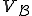 shows it, we have:
shows it, we have:
Proposition 12. Given a recursive function 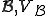 is .
is .
Theorem 13. There are some functions for which is -complete.
Proof. Suppose now given a computable function 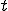 , it has an index . It is well known that the set
, it has an index . It is well known that the set 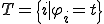 is
is 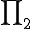 -complete. Define now
-complete. Define now 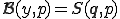 . Observe that a virus verify:
. Observe that a virus verify: 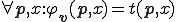 . The pairing procedure being surjective, is an index of . Conversly, suppose that is not a virus. In that case, there is some
. The pairing procedure being surjective, is an index of . Conversly, suppose that is not a virus. In that case, there is some 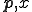 for which
for which 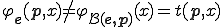 . As a consequence, it is not an index of . So,
. As a consequence, it is not an index of . So, 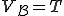 .
.
Theorem 14. There are some functions for which it is decidable whether is a virus or not.
Proof. Let us define 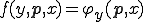 . Being recursive, it has a code, say . Application of s-m-n Theorem provides
. Being recursive, it has a code, say . Application of s-m-n Theorem provides 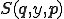 such that for all
such that for all 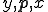 , we have
, we have 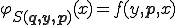 . Let us define
. Let us define 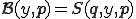 . It is routine to check that for all
. It is routine to check that for all 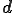 , is a virus for . So, in that case, any index is a virus.
, is a virus for . So, in that case, any index is a virus.
A consequence of this is that there are some weakness for which it is decidable whether a code is a virus or not. This is again, as far as we know, one of the first positive results concerning the detection of viruses.
A method widely used for virus detection is file scanning. It uses short strings, refered as signatures, resulting from reverse engineering of viral codes. Those signatures only match the considered virus and not healthy programs. Thus, using a search engine, if a signature is found a virus is detected.
To avoid this detection, one could consider and old virus and change some instructions in order to fool the signature recognition. As an illustration, consider the following signature of a viral bash code
The following code denotes the same program but with an other signature
Polymorphic viruses use this idea, when it replicates, such a virus changes some parts of its code to look different.
Virus writers began experimenting with such techniques in the early nineties and it achieved with the creation of mutation engines. Historically the first one was "Dark Avenger". Nowadays, many mutation engines have been released, most of them use encryption, decryption functions. The idea, is to break the code into two parts, the first one is a decryptor responsible for decrypting the second part and passing the control to it. Then the second part generates a new decryptor, encrypts itself and links both parts to create a new version of the virus.
A polymorphic virus could be illustrated by the following bash code, it is a simple virus which use as polymorphic engine a swap of two characters.
To detect polymorphic computer viruses, anti virus editors have used code emulation techniques and static analysers. The idea of emulation, is to execute programs in a controled fake environment. Thus an encrypted virus will decrypt itself in this environment and some signature detection can be done. Concerning static analysers, they are improved signature maching engines which are able to recognize simple code variation.
To thward those methods, since 2001 virus writers has investigated metamorphism. This is an enhanced morphism technique. Where polymorphic engines generate a variable encryptor, a metamorhic engine generates a whole variable code using some obfuscation functions. Moreover, to fool emulation methods metamorphic viruses can alter their behavior if they detect a controled environment.
When it is executed, a metamorphic virus desassembles its own code, reverse engineers it and transforms it using its environment. If it detects that his environment is controled, it transforms itself into a healthy program, else it recreates a new whole viral code using reverse ingineered information, in order to generate a replication semantically indentical but programmatically different.
Such a virus is really difficult to analyse, thus it could take a long period to understand its behavior. During this period, it replicates freely.
Intuitively, polymorphic viruses mutates without concidering their environment whereas metamophic viruses spawn their next generation using new information. As a matter of fact, to capture this notion, one must consider the equation in its entirety.